Lately, the SPAM problem got a lot worse in my email INBOX. Spammers seem to more and more check if their mail gets flagged by SpamAssasin and tweak the messages until they get through.
Due to some tricky aliasing going on on the mail server, I’m unable to properly use the bayes filter of SpamAssasin on our main mail server. You see, I have an infinite amount of addresses which are in the end delivered to the same account and all that aliasing can only be done after the message has passed SpamAssassin.
This means that even though mail may go to one and the same user in the end, it’s seen as mail for many different users by SpamAssassin.
This inability to use Bayes with SpamAssassin means that lately, SPAM has been getting through the filter.
So much SPAM that I began getting really, really annoyed.
I know that mail clients themselves also have bayes based SPAM filters, but I often check my email account with my mobile phone or on different computers, so I’m dependent on a solution that filters out the SPAM before it reaches my INBOX on the server.
The day before yesterday I had enough.
While all mail for all domains I’m managing is handled by a customized MySQL-Exim-Courier setting, mail to the @sensational.ch domain is relayed to another server and then delivered to our exchange server.
Even better: That final delivery step is done after all the aliasing steps (the catch-all aliases being the difficult part here) have completed. This means that I can in-fact have all mail to @sensational.ch pass through a bayes filter and the messages will all be filtered for the correct account.
This made me install dspam on the relay that transmits mail from our central server to the exchange server.
Even after only one day of training, I’m getting impressive results: DSPAM only touches mail that isn’t flagged as spam by SpamAssassin, which means that it’s carefully crafted to look “real”.
After one day of training, DSPAM usually detects junk messages and I’m down to one false negative every 10 junk messages (and no false positives).
Even after running SpamAssassin and thus filtering out the obvious suspects, a whopping 40% of emails I’m receiving are SPAM. So nearly half of the messages not already filtered out by SA are still SPAM.
If I take a look at the big picture, even when counting the various mails sent by various cron daemons as genuine email, I’m getting much more junk email than genuine email per day!
Yesterday, tuesday, for example, I got – including mails from cron jobs and backup copies of order confirmations for PopScan installations currently in public tests – 62 genuine emails and 252 junk mails of which 187 were caught by SpamAssassin and the rest was detected by DSPAM (with the exception of two mails that got through).
This is insane. I’m getting four times more spam than genuine messages! What the hell are these people thinking? With that volume of junk filling up our inboxes how ever could one of these “advertisers” think that somebody is both stupid enough to fall for such a message and intelligent enough to pick the one to fall for from all the others?
Anyways. This isn’t supposed to be a rant. It’s supposed to be a praise to DSPAM. Thanks guys! You rule!
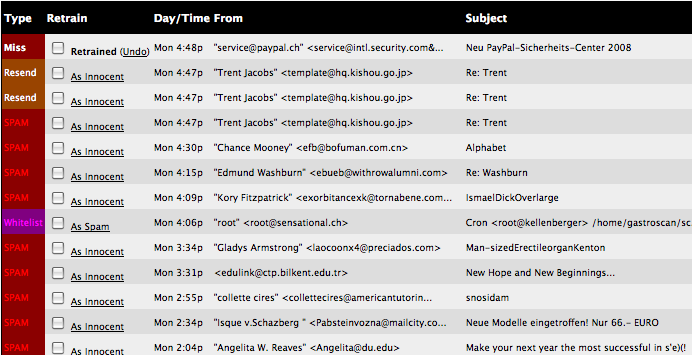 <p>I don’t see much point in complaining about SPAM, but it’s slowly but surely reaching complete insanity…</p>
<p>I don’t see much point in complaining about SPAM, but it’s slowly but surely reaching complete insanity…</p>