As I’ve stated previously, I’m subscribed to what is probably the coolest ISP on earth. Between the full symmetric Gbit/s, their stance on network neutrality, their IPv6 support and their awesome support even for advanced things like setting up an IPv6 reverse DNS delegation(!), there’s nothing you could ever wish for from an ISP.
For some time now, they have also provided an IPTV solution as an additional subscription called tv7.
As somebody who last watched live tv around 20 years ago, I wasn’t really interested to subscribe to that. However, contrary to many other IPTV solutions what’s special about the Fiber7 solution is that they are using IP multicast to deliver the unaltered DVB frames to their users.
For people interested in TV, this is great because it’s, for all intents and purposes, lag free as the data is broadcast directly through their network where interested clients can just pick it up (of course there will be some <1ms lag for the data to move through their network plus some additional <1ms lag as your router forwards the packets to your internal network).
As I never dealt with IP multicast, this was an interesting experiment for me, and when they released their initial offering, they provided a test-stream to see whether your infrastructure was multicast ready or not.
Back then, I never got it to work behind my PFSense setup but as I wasn’t interested in TV, I never bothered spending time on this, though it did hurt my pride.
Fast forward to about three weeks ago where I made a comment on twitter about that pride being hurt to the CEO of fiber7. He informed me that the test stream was down, but then he also sent me a DM to ask me whether I was interested in trying out their tv7 offering, including the beta version of their app for the AppleTV.
That was one evil way to nerd-snipe me, so naturally, I told him that, yes, I would be interested, but that I wasn’t really ever going to use it aside of just getting it to work, because live TV just doesn’t interest me.
Despite the fact that it was past 10pm, he sent me another DM, telling me that he has enabled tv7 for my account.
The rest of the night I spent experimenting with IGMP Proxy and the PFSense firewall to some varying success, but on the next day I was finally successful
You might notice that this is a screenshot of VLC. That’s no coincidence: While Fiber7 officially only supports the AppleTV app, they also offer links on a support page of theirs to m3u and xspf playlists that can be used by advanced users (which is another case of Fiber7 being awesome), so while debugging to make this work, I definitely preferred to using VLC which had a proper debug log.
After I got it to work, I also found a bug in the Beta version of the Fiber7 app where it would never unsubscribe from a multicast group, causing the traffic to my LAN to increase whenever I would switch channels in the app. The traffic wouldn’t decrease even if the AppleTV went to sleep – only a reboot would help.
I’ve reported this to Fiber7 and within a day or two, a new release was pushed to TestFlight in order to fix the issue.
Since this little adventure happened, Fiber7 has changed their offering: Now every Fiber7 account gets free access to tv7 which will probably broaden the possible audience quite a bit.
Which brings me to the second point of this post: To show you the configuration needed if you’re using a PFSense based gateway and you want to make use of tv7.
First, you have to enable the IGMP proxy:
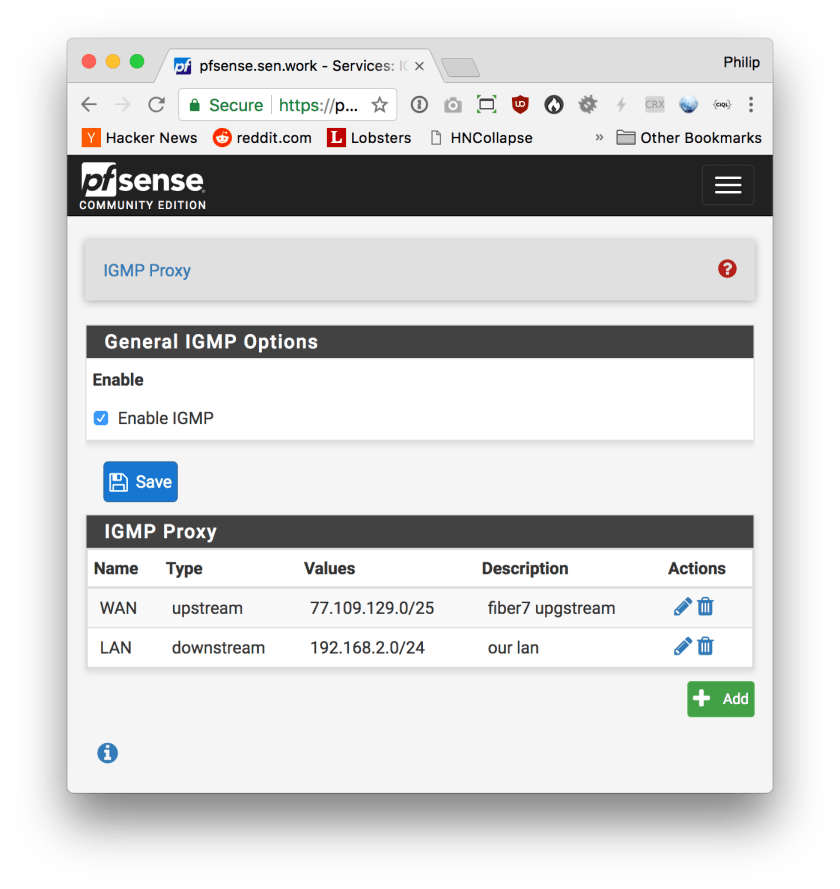
For the LAN interface, please type in the network address and netmask of your internal IPv4 LAN.
What IGMP Proxy does is to listen to clients in your LAN joining to a multicast group and then joining on their behalf on the upstream interface. It will then forward all traffic received on the upstream aimed at the group to the group on the downstream interface. This is where the additional small bit of lag is added, but this is the only way to have multicast cross routing barriers.
This is also mostly done on your routers CPU, but at the 20MBit/s a stream consumes, this shouldn’t be a problem on more or less current hardware.
Anyways – if you want to actually watch TV, you’re not done yet because even though this service is now running, the built-in firewall will drop any packets related to multicast joining and all actual multicast packets containing the video frames.
So the next step is to update the firewall:
Create the following rules for your WAN interface:

You will notice that little gear icon next to the rule. What that means is that additional options are enabled. The extra option you need to enable is this one here:

I don’t really like the second of the two rules. In principle, you only need to allow a single IP: The one of your upstream gateway. But that might change whenever your IPv4 address changes and I don’t think you will want to manually update your firewall rule every time.
Instead, I’m allowing all IGMP traffic from the WAN net, trusting Fiber7 to not leak other subscriber’s IGMP traffic to my network.
Unfortunately, you’re still not quite done.
While this configures the rules for the WAN interface, the default “pass all” rule on the LAN interface will still drop all video packets because the above “Allow IP options” checkbox is off by default for the default pass all rule.
You have to update that too on the “LAN” interface:
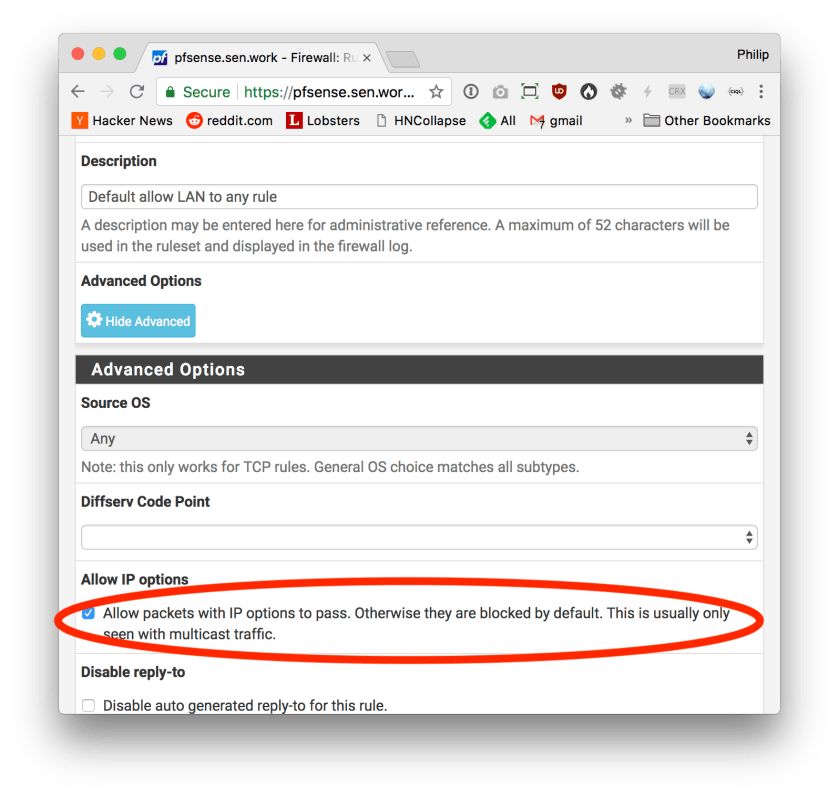
And that’s all.
The network I’m listing there, 77.109.128.0/19 is not documented officially. Fiber7 might change that at any time at which point your nice setup will stop working and you’ll have to update the IGMP Proxy and Firewall configuration.
In my case, I’ve determined the network address by running
/usr/local/sbin/igmpproxy -d -vvvv /var/etc/igmpproxy.conf
and checking out the error message where igmpproxy was not allowing traffic to an unknown network. I’ve then looked up the network of the address using whois and updated my config accordingly.