Lately I was having an issue with a Lion Server that refused logins of users stored in OpenDirectory. A quick check of /var/log/opendirectoryd.log revealed an issue with the «Password Server»:
Module: AppleODClient - unable to send command to Password Server - sendmsg() on socket fd 16 failed: Broken pipe (5205)
As this message apparently doesn’t appear on Google yet, there’s my contribution to solving this.
The fix was to kill -9 the kerberos authentication daemon:
sudo killall kpasswdd
which in fact didn’t help (sometimes even sudo isn’t enough), so I had to be more persuasive to get rid of the apparently badly hanging process:
sudo killall -9 kpasswdd
This time the process was really killed and subsequently instantly restarted by launchd.
When you call serialize() in PHP, to serialize a value into something that you store for later use with unserialize(), then be very careful what you are doing with that data.
When you look at the output, you’d be tempted to assume that it’s text data:
You will notice that the format encodes the strings length together with the string. And because PHP is inherently not unicode capable, it’s not encoding the strings character length, but its byte-length.
unserialize() checks whether the encoded length matches the actual delimited strings length. This means that if you treat the serialized output as text and your databases’s encoding changes along the way, that the retrieved string can’t be unserialized any more.
I just learned that the hard way (even though it’s obvious in hindsight) while migrating PopScan from ISO-8859-1 to UTF-8:
The databases of existing systems now contain a lot of output from serialize() which was run over ISO strings but now that the client-encoding in the database client is set to utf-8, the data will be retrieved as UTF-8 and because the serialize() output was stored in a TEXT column, it happily gets UTF-8 encoded.
If we remove the database from the picture and express the problem in code, this is what’s going on:
unserialize(utf8encode(serialize('data with 8bit chàracters')));
i.e the data gets altered after serializing and the way it gets altered is a way that unserialize can’t deal with the data any more.
So, for everybody else not yet in this dead end:
The output of serialize() is binary data. It looks like textual data, bit it isn’t. Treat it as binary. If you store it somewhere, make sure that the medium you store it to treats the data as binary. No transformation what so ever must ever be made on it.
Of course, that leaves you with a problem later on if you switch character sets and you have to unserialize, but at least you get to unserialize then. I have to go great lengths now to salvage the old data.
UUID have the very handy property that they are uniqe and there are quite many of them for you to use. Also they are difficult to guess and knowing the UUID of one object, it’s very hard to guess a valid UUID of another object.
This makes UUIDs perfect for identifying things in web applications:
Even if you shard across multiple machines, each machine can independently generate primary keys without (realistic) fear of overlapping.
You can generate them without using any kind of locks.
Sometimes, you have to expose such keys to the user. If possible, you will of course do authorization checks, but it still makes sense not allowing users know about neighboring keysThis gets even more important when you are not able to do authorization keys because the resource you are referring to is public (like a mail alias) but it should still not possible to know other items if you know one.
Knowing that UUIDs are a good thing, you might want to use them in your application (or you just have to in the last case above).
There are multiple recipes out there that show how to do it in a rails application (this one for example).
All of these recipes store UUIDs as varchar’s in your database. In general, that’s fine and also the only thing you can do as most databases don’t have a native data type for UUIDs.
PostgreSQL the other hand indeed has a native 128 bit integer type to store UUID.
This is more space efficient than storing the UUID in string form (288 bit) and it might be a tad bit faster when doing comparison operations on the database as integer operations (even if they are this big) require a constant amount of operations whereas comparing two string UUIDs is a string comparison which is dependent on the string size and size of the matching parts.
So maybe for the (minuscule) speed increase or for the purpose of correct semantics or just for interoperability with other applications, you might want to use native PostgreSQL UUIDs from your Rails (or other, but without the abstraction of a “Migration”, just using UUID is trivial) applications.
This already works quite nicely if you generate the columns as strings in your migrations and then manually send an alter table (whenever you restore the schema from scratch).
But if you want to create the column with the correct type directly from the migration and you want the column to be created correctly when using rake db:schema:load, then you need a bit of additional magic, especially if you want to still support other databases.
In my case, I was using PostgreSQL in production (whatelse?), but on my local machine, for the purpose of getting started quickly, I wanted to still be able to use SQLite for development.
In the end, everything boils down to monkey patching ActiveRecord::ConnectionAdapters::Adapters and PostgreSQLColumn of the same module. So here’s what I’ve addded to config/initializers/uuuid_support.rb (Rails 3.0.):
Maybe with a bit better Ruby knowledge than I have, it should be possible to just monkey-patch the parent AbstractAdaper while still calling the method of the current subclass. This would not require a separate patch for all adapters in use.
For my case which was just support for SQLite and PostgreSQL, the above initializer was fine though.
There was a discussion on HackerNews about Gmail having lost the email in some accounts. One sentiment in the comments was clear:
It’s totally the users problem if they don’t back up their cloud based email.
Personally, I think I would have to agree:
Google is a provider like every other ISP or basically any other service too. There’s no reason to believe that your data is more save on Google than it is any where else. Now granted, they are not exactly known for losing data, but there’s other things that can happen.
Like your account being closed because whatever automated system believed your usage patterns were consistent with those of a spammer.
So the question is: What would happen if your Google account wasn’t reachable at some point in the future?
For my company (using commercial Google Apps accounts), I would start up that IMAP server which serves all mail ever sent to and from Gmail. People would use the already existing webmail client or their traditional IMAP clients. They would lose some productivity, but no single byte of data.
This was my condition for migrating email over to Google. I needed to have a back up copy of that data. Otherwise, I would not have agreed to switch to a cloud based provider.
The process is completely automated too. There’s not even a backup script running somewhere. Heck, not even the Google Account passwords have to be stored anywhere for this to work.
So. How does it work then?
Before you read on, here are the drawbacks of the solution:
I’m a die-hard Exim fan (long story. It served me very well once – up to saving-my-ass level of well), so the configuration I’m outlining here is for Exim as the mail relay.
Also, this only works with paid Google accounts. You can get somewhere using the free ones, but you don’t get the full solution (i.e. having a backup of all sent email)
This requires you to have full control over the MX machine(s) of your domain.
If you can live with this, here’s how you do it:
First, you set up your Google domain as normal. Add all the users you want and do everything else just as you would do it in a traditional set up.
Next, we’ll have to configure Google Mail for two-legged OAuth access to our accounts. I’ve written about this before. We are doing this so we don’t need to know our users passwords. Also, we need to enable the provisioning API to get access to the list of users and groups.
Next, our mail relay will have to know about what users (and groups) are listed in our Google account. Here’s what I quickly hacked together in Python (my first Python script ever – be polite while flaming) using the GData library:
Place this script somewhere on your mail relay and run it in a cron job. In my case, I’m having its output redirected to /etc/exim4/gmail_accounts. The script will emit one user (and group) name per line.
Next, we’ll deal with incoming email:
In the Exim configuration of your mail relay, add the following routers:
yourdomain_gmail_users is what creates the local copy. It accepts all mail sent to yourdomain.com, if the local part (the stuff in front of the @) is listed in that gmail_accounts file. Then it sets up some paths for the local transport (see below) and marks the mail as unseen so the next router gets a chance too.
Which is yourdomain_gmail_remote. This one is again checking domain and the local part and if they match, it’s just delegating to the gmail_t remote transport (which will then send the email to Google).
the gmail_t transport is simple. The local one you might have to patch up users and groups plus the location where you what to write the mail to.
Now we are ready to reconfigure Google as this is all that’s needed to get a copy of every inbound mail into a local maildir on the mail relay.
Here’s what you do:
You change the MX of your domain to point to this relay of yours
The next two steps are the reason you need a paid account: These controls are not available for the free accounts:
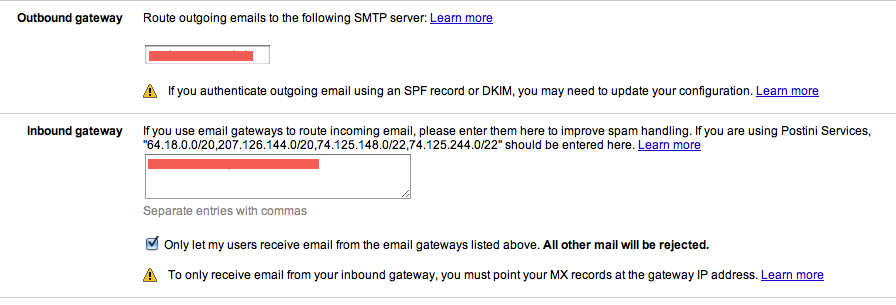
In your Google Administration panel, you visit the Email settings and configure the outbound gateway. Set it to your relay.
Then you configure your inbound gateway and set it to your relay too (and to your backup MX if you have one).
This screenshot will help you:
All email sent to your MX (over the gmail_t transport we have configured above) will now be accepted by gmail.
Also, Gmail will now send all outgoing Email to your relay which needs to be configured to accept (and relay) email from Google. This pretty much depends on your otherwise existing Exim configuration, but here’s what I added (which will work with the default ACL):
And lastly, the tricky part: Storing a copy of all mail that is being sent through Gmail (we are already correctly sending the mail. What we want is a copy):
The maildir I’ve chosen is the correct one if the IMAP-server you want to use is Courier IMAPd. Other servers use different methods.
One little thing: When you CC or BCC other people in your domain, Google will send out multiple copies of the same message. This will yield some message duplication in the sent directory (one per recipient), but as they say: Better backup too much than too little.
Now if something happens to your google account, just start up an IMAP server and have it serve mail from these maildir directories.
And remember to back them up too, but you can just use rsync or rsnapshot or whatever other technology you might have in use. They are just directories containing one file per email.
Like so many times before, today I was yet again in the situation where I wanted to know which tables/indexes take the most disk space in a particular PostgreSQL database.
My usual procedure in this case was to dt+ in psql and scan the sizes by eye (this being on my development machine, trying to find out the biggest tables I could clean out to make room).
But once you’ve done that a few times and considering that dt+ does nothing but query some PostgreSQL internal tables, I thought that I want this solved in an easier way that also is less error prone. In the end I just wanted the output of dt+ sorted by size.
The lead to some digging in the source code of psql itself (src/bin/psql) where I quickly found the function that builds the query (listTables in describe.c), so from now on, this is what I’m using when I need to get an overview over all relation sizes ordered by size in descending order:
Of course I could have come up with this without source code digging, but honestly, I didn’t know about relkind s, about pg_size_pretty and pg_relation_size (I would have thought that one to be stored in some system view), so figuring all of this out would have taken much more time than just reading the source code.
Now it’s here so I remember it next time I need it.
While working on my day job, we are often dealing with huge data tables in HTML augmented with some JavaScript to do calculations with that data.
Think huge shopping cart: You change the quantity of a line item and the line total as well as the order total will change.
This leads to the same data (line items) having three representations:
The model on the server
The HTML UI that is shown to the user
The model that’s seen by JavaScript to do the calculations on the client side (and then updating the UI)
You might think that the JavaScript running in the browser would somehow be able to work with the data from 2) so that the third model wouldn’t be needed, but due to various localization issues (think number formatting) and data that’s not displayed but affects the calculations, that’s not possible.
So the question is: Considering we have some HTML templating language to build 2), how do we get to 3).
Back in 2004 when I initially designed that system (using AJAX before it was widely called AJAX even), I hadn’t seen Crockford’s lectures yet, so I still lived in the “JS sucks” world, where I’ve done something like this
<!-- lots of TRs --><tr><td>Column 1 addSet(1234 /*prodid*/, 1 /*quantity*/, 10 /*price*/, /* and, later, more, stuff, so, really, ugly */)</td><td>Column 2</td><td>Column 3</td></tr><!-- lots of TRs -->
(Yeah – as I said: 2004. No object literals, global functions. We had a lot to learn back then, but so did you, so don’t be too angry at me – we improved)
Obviously, this doesn’t scale: As the line items got more complicated, that parameter list grew and grew. The HTML code got uglier and uglier and of course, cluttering the window object is a big no-no too. So we went ahead and built a beautiful design:
The first iteration was then parsing that JSON every time we needed to access any of the associated data (and serializing again whenever it changed). Of course this didn’t go that well performance-wise, so we began caching and did something like this (using jQuery):
Now each DOM element representing one of these <tr>’s had a ps_data member which allowed for quick access. The JSON had to be parsed only once and then the data was available. If it changed, writing it back didn’t require a re-serialization either – you just changed that property directly.
This design is reasonably clean (still not as DRY as the initial attempt which had the data only in that JSON string) while still providing enough performance.
Until you begin to amass datasets. That is.
Well. Until you do so and expect this to work in IE.
800 rows like this made IE lock up its UI thread for 40 seconds.
So more optimization was in order.
First,
$('.lineitem')
will kill IE. Remember: IE (still) doesn’t have getElementsByClassName, so in IE, jQuery has to iterate the whole DOM and check whether each elements class attribute contains “lineitem”. Considering that IE’s DOM isn’t really fast to start with, this is a HUGE no-no.
So.
$('tr.lineitem')
Nope. Nearly as bad considering there are still at least 800 tr’s to iterate over.
$('#whatever tr.lineitem')
Would help if it weren’t 800 tr’s that match. Using dynaTrace AJAX (highly recommended tool, by the way) we found out that just selecting the elements alone (without the iteration) took more than 10 seconds.
So the general take-away is: Selecting lots of elements in IE is painfully slow. Don’t do that.
But back to our little problem here. Unserializing that JSON at DOM ready time is not feasible in IE, because no matter what we do to that selector, once there are enough elements to handle, it’s just going to be slow.
Now by chunking up the amount of work to do and using setTimeout() to launch various deserialization jobs we could fix the locking up, but the total run time before all data is deserialized will still be the same (or slightly worse).
So what we have done in 2004, even though it was ugly, was way more feasible in IE.
Which is why we went back to the initial design with some improvements:
Loading time went back to where it was in the 2004 design. It was still bad though. With those 800 rows, IE was still taking more than 10 seconds for the rendering task. dynaTrace revealed that this time, the time was apparently spent rendering.
The initial feeling was that there’s not much to do at that point.
Until we began suspecting the script tags.
Doing this:
<!-- lots of TRs --><trclass="lineitem"><td>Column 1</td><td>Column 2</td><td>Column 3</td></tr><!-- lots of TRs -->
The page loaded instantly.
Doing this
<!-- lots of TRs --><trclass="lineitem"><td>Column 1 1===1;</td><td>Column 2</td><td>Column 3</td></tr><!-- lots of TRs -->
it took 10 seconds again.
Considering that IE’s JavaScript engine runs as a COM component, this isn’t actually that surprising: Whenever IE hits a script tag, it stops whatever it’s doing, sends that script over to the COM component (first doing all the marshaling of the data), waits for that to execute, marshals the result back (depending on where the DOM lives and whether the script accesses it, possibly crossing that COM boundary many, many times in between) and then finally resumes page loading.
It has to wait for each script because, potentially, that JavaScript could call document.open() / document.write() at which point the document could completely change.
So the final solution was to loop through the server-side model twice and do something like this:
<!-- lots of TRs --><trclass="lineitem"><td>Column 1 </td><td>Column 2</td><td>Column 3</td></tr><!-- lots of TRs --></table>
PopScan.LineItems.add({prodid: 1234, quantity: 1, price: 10, foo: "bar", blah: "blah"});
// 800 more of these
Problem solved. Not too ugly design. Certainly no 2004 design any more.
And in closing, let me give you a couple of things you can do if you want to bring the performance of IE down to its knees:
Use broad jQuery selectors. $('.someclass') will cause jQuery to loop through all elements on the page.
Even if you try not to be broad, you can still kill performance: $('div.someclass'). The most help jQuery can expect from IE is getElementsByTagName, so while it’s better than iterating all elements, it’s still going over all div’s on your page. Once it’s more than 200, the performance extremely quickly falls down (probably doing some O(n^2) thing somehwere).
Use a lot of <script>-tags. Every one of these will force IE to marshal data to the scripting engine COM component and to wait for the result.
Next time, we’ll have a look at how to use jQuery’s delegate() to handle common cases with huge selectors.
For a geek like me, the Nokia N900 is paradise on earth: It’s full Debian Linux in your bag. It has the best IM integration I have ever seen on any mobile device. It has the best VoIP (Skype, SIP) integration I have ever seen on any mobile device and it has one of the coolest multitasking implementations I’ve seen on any mobile device (the card-based task/application switching is fantastic).
Unfortunately, there’s one thing that prevents me from using it (or many other phones) to replace my iPhone: While the whole world agreed on one way to wire a microphone/headphone combination, Apple thought it wise to do it another way, which leads to Apple compatible headsets not working with the N900.
By not working I don’t just mean “no microphone” or even “no sound”. No. I mean “deafening buzzing on both the left and right channel and headset still not being recognized in the software”.
The problem is that I already own iPhone compatible headsets and that it’s way easier to get good iPhone compatible ones around here. I’m constantly listening to audio on my phone (Podcast, Audiobooks). Having to grab the phone out of my bag and unplugging the headphones whenever it rings is inacceptable to me, so I need to have a microphone with my headphones.
Just now though, I found a small adapter which promises to solve that problem, proving once again, that there’s nothing that’s not being sold on the internet.
I ordered one (thankfully one of the international shipping options was less than the adapter itself – something I’m not used to with the smaller stores), so we’ll see how that goes. If it means that I can use a N900 as my one and only device, I’ll be a very happy person indeed.
Recently, while reading through the log file of the mail relay used by tempalias, I noticed a disturbing trend: Apparently, SPAM was being sent through tempalias.
I’ve seen various behaviours. One was to strangely create an alias per second to the same target and then delivering email there.
While I completely fail to understand this scheme, the other one was even more disturbing: Bots were registering {max-usage: 1, days: null} aliases and then sending one mail to them – probably to get around RBL checks they’d hit when sending SPAM directly.
Aside of the fact that I do not want to be helping spammers, this also posed a technical issue: node.js head which I was running back when I developed the service tended to leak memory at times forcing me to restart the service here and then.
Now the additional huge load created by the bots forced me to do that way more often than I wanted to. Of course, the old code didn’t run on current node any more.
Hence I had to take tempalias down for maintenance.
the tempalias SMTP daemon now does RBL checks and immediately disconnects if the connected host is listed.
the tempalias HTTP daemon also does RBL checks on alias creation, but it doesn’t check the various DUL lists as the most likely alias creators are most certainly listed in a DUL
Per IP, aliases can only be generated every 30 seconds.
This should be some help. In addition, right now, the mail relay is configured to skip sender-checks and sa-exim scans (Spam Assassin on SMTP time as to reject spam before even accepting it into the system) for hosts where relaying is allowed. I intend to change that so that sa-exim and sender verify is done regardless if the connecting host is the tempalias proxy.
Looking at the mail log, I’ve seen the spam count drop to near-zero, so I’m happy, but I know that this is just a temporary victory. Spammers will find ways around the current protection and I’ll have to think of something else (I do have some options, but I don’t want to pre-announce them here for obvious reasons).
On a more happy note: During maintenance I also fixed a few issues with the Bookmarklet which should now do a better job at not coloring all text fields green eventually and at using the target site’s jQuery if available.
Yesterday I ran into an interesting problem with Windows 2008’s implementation of NAT (don’t ask – this was the best solution – I certainly don’t recommend using Windows for this purpose).
Whenever I enabled the NAT service, I was unable to reliably connect to the machine via remote desktop or even any other service that machine was offering. Packets sent to the machine were dropped as if a firewall was in between, but it wasn’t and the Windows firewall was configured to allow remote desktop connections.
Strangely, sometimes and from some hosts I was able to make a connection, but not consistently.
After some digging, this turned out to be a problem with the interface metrics and the server tried to respond over the interface with the private address that wasn’t routed.
So if you are in the same boat, configure the interface metrics of both interfaces manually. Set the metric of the private interface to a high value and the metrics of the public (routed) one to a low value.
At least for me, this instantly fixed the problem.
Our company uses Google Apps premium for Email and shared documents, but in order to have more freedom in email aliases, in order to have more control over email routing and finally, because there are a couple of local parts we use to direct mail to some applications, all our mail, even though it’s created in Google Apps and finally ends up in Google Apps, goes via a central mail relay we are running ourselves (well. I’m running it).
Google Apps premium allows you to do that and it’s a really cool feature.
One additional thing I’m doing on that central relay is to keep a backup of all mail that comes from Google or goes to Google. The reason: While I trust them not to lose my data, there are stories around of people losing their accounts to Googles anti-spam automatisms. This is especially bad as there usually is nobody to appeal to.
So I deemed it imperative that we store a backup of every message so we can move away from google if the need to do so arises.
Of course that means though that our relay needs to know what local parts are valid for the google apps domain – after all, I don’t want to store mail that would later be bounced by google. And I’d love to bounce directly without relaying the mail unconditionally, so that’s another reason why I’d want to know the list of users.
Google provides their provisioning API to do that and using the GData python packages, you can easily access that data. In theory.
Up until very recently, the big problem was that the provisioning API didn’t support OAuth. That meant that my little script that retreives the local parts had to have a password of an administrator which is something that really bugged me as it meant that either I store my password in the script or I can’t run the script from cron.
With the Google Apps Marketplace, they fixed that somewhat, but it still requires a strange dance:
This is totally not true though as Google’s definition of “all” apparently doesn’t include “Provisioning” :-)
To make two-legged OAuth work for the provisioning API, you have to explicitly list the feeds. In my case, this was Users and Groups:
Under “Client Name”, add your domain again (“example.com”) and unter One or More API Scopes, add the two feeds like this: “https://apps-apis.google.com/a/feeds/group/#readonly,https://apps-apis.google.com/a/feeds/user/#readonly”
This will enable two-legged OAuth access to the user and group lists which is what I need in my little script:
importgdata.apps.serviceimportgdata.apps.groups.serviceconsumer_key='YOUR.DOMAIN'consumer_secret='secret'#check advanced / OAuth in you control panelsig_method=gdata.auth.OAuthSignatureMethod.HMAC_SHA1service=gdata.apps.service.AppsService(domain=consumer_key)service.SetOAuthInputParameters(sig_method,consumer_key,consumer_secret=consumer_secret,two_legged_oauth=True)res=service.RetrieveAllUsers()forentryinres.entry:printentry.login.user_nameservice=gdata.apps.groups.service.GroupsService(domain=consumer_key)service.SetOAuthInputParameters(sig_method,consumer_key,consumer_secret=consumer_secret,two_legged_oauth=True)res=service.RetrieveAllGroups()forentryinres:printentry['groupName']