As I write these words, I have just finally disabled our LDAP/Active Directory server based on Samba which is incredibly hard to update, to backup and to re-create in case of emergencies.
We’ve traditionally used Gmail for Email and Calendar access and LDAP/Active Directory for everything else: The office WLAN, VPN access, internal support tool access, SSH access, you name it.
However, that solution came with operational drawbacks for us:
- Unix support for Active Directory is flaky at best and the UI that Windows once provided for setting up LDAP attributes required for Unix users has stopped working with Windows 8
- Samba is hard to install and keep up to date. Setting up an Active Directory domain creates a ton of local state that’s difficult to back up and impossible to put into a configuration management system.
- The LDAP server being reachable is a prerequisite for authentication on machines to work. This meant that tunnels needed to be created for various machines to have access to that.
- Each Debian update came with new best practice for LDAP authentication of users, so each time new tools and configuration needed to be learned, tested and applied.
- As we’re working with contractors giving temporary access to our support tools is difficult because we need to create temporary LDAP accounts for them.
- Any benefits that could have been had by having workstations use a centralized user account database have evaporated over time as our most-used client OS (macOS) lost more and more central directory support.
On the other hand, everybody at our company has a GitHub account and so do contractors, so we’re already controlling user access via GitHub.
GitHub provides excellent support for account security too, especially once we could force 2FA to be enabled on all users. Also over time, the reliance on locally installed tools grew smaller and smaller when on the other hand, most cloud services were making use of provide OAuth Sign-in-with-Github functionality.
It became clear that stuff would work ever so much better if only we could get rid of that LDAP/Active Directory thing.
So I started a multi-year endeavor to get rid of LDAP. It wouldn’t have needed to be multi-year, but as this happened mostly as side-projects, I tackled them whenever I had the opportunity.
I’m fully aware that this puts us into the position where we’re dependent on our Github subscription to be active. But so does a lot of our daily development work. We use Issues, Pull Requests, GitHub Actions, you name it. While git itself is, of course, decentralized, all the other services provided by GitHub are not.
Then again, while we would be in a really bad spot with regards to our development processes, unhooking our glue code from GitHub and changing it to a traditional username/password solution would be very feasible even in a relative short time-frame (much shorter than the disruption to the rest of our processes).
Which means that I’m ready to increase the dependency on GitHub even more and use them as our identity provider.
The first thing to change was the internal support tools our support team uses to get authenticated access to our sites for support purposes. The interface between that tool and the sites has always been using signed access tickets (think JWT but slightly different, mostly because pre-dating JWT by about 5 years) to give users access. The target site itself did not need access to LDAP, only the support tool needed it to authenticate our support team members.
So unhooking that tool from LDAP and hooking it up to Github was the first step. Github has well-documented support for writing OAuth client apps to authenticate users.
Next was authenticating users to give SSH access to production machines. This was solved by teaching our support tool how to sign SSH public keys and by telling the production machines to trust that CA.
I wrote a small utility in Swift to send an SSH public key to the support tool to have it signed and to install the certificate in the SSH agent. The certificates have a short lifetime ranging from one day to at most one week (depending on user) and using the GitHub API, the central tool knows about team memberships which allows us to confer different permissions on different servers based on team membership.
None of the SSH servers can do all of the certificate validation entirely locally (due to the short lifetime we can live without a CRL), independent of network access (which there is none of for some machines).
Which meant that SSH access is now possible independently of LDAP and even network availability. And it’s using a mechanism that’s very simple and comes with zero dependencies aside of openssh itself.
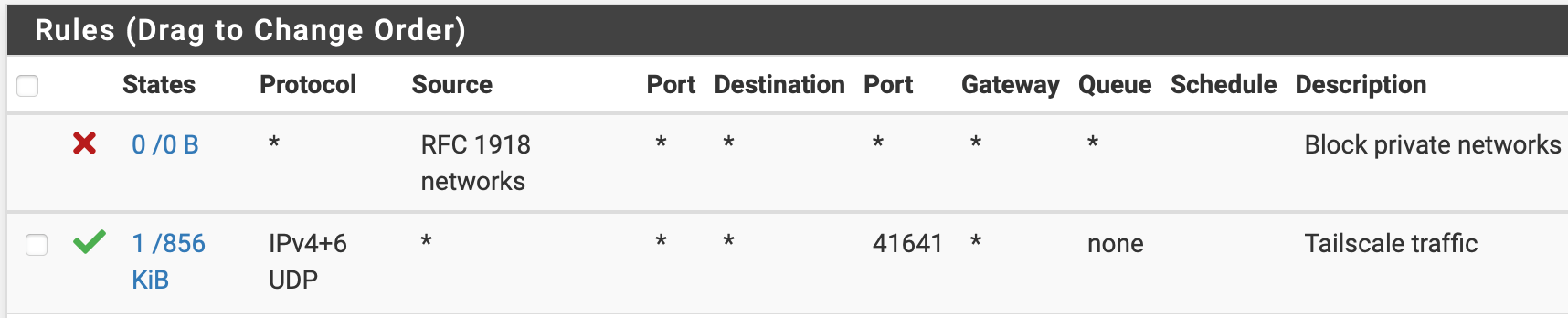
Then came the VPN. I’ve run IPSec with IKEv2 to provide authenticated access to parts of the production network. It (or rather the RADIUS server it used) needed access to LDAP and even though it was using stock PFSense IPSec support, it was unreliable and needed restarts with some regularity.
This was entirely replaced by a SSH bastion host and ProxyJump in conjunction with above SSH certificates. No more LDAP and production access based on GitHub group membership of GitHub accounts. While it never happened and I would be very wary of allowing it, this would allow us to give selective access to machines to contractors based on nothing but their GitHub account (and who doesn’t have one of those these days).
Behind the production network, there’s another, darker part of the infrastructure. That’s the network where all the remote management interfaces and the virtual machine hosts are connected to. This one is absolutely critical and access to it is naturally very restricted.
The bastion host described above does not have access to that network.
In comes the next hat our support tool/github integration is wearing: It can synchronize Tailscale ACLs with Github and it can dynamically alter the ACL to give temporary access to specific users.
Tailscale itself uses Github as an identity provider too (and also supports custom identity providers, so, again, losing GitHub for this would not be the end of the world) and our support tool uses the GitHub and Tailscale APIs to make sure that only users in a specific GitHub group get access to Tailscale at all.
So everybody who needs network access that’s not doable or not convenient via the SSH bastion host has a Tailscale account (very few) and of those even fewer users are in a GitHub Team that causes our support tool to allow for such users to request temporary (30 min max) access to the super secret backstage network.
Which completely removes the last vestiges of the VPN from the picture and leaves us with just one single dependency: The office wifi.
Even though the office network really isn’t in a privileged position (any more), I want access to that network to be authenticated and I want to be able to revoke access to individual users.
Which is why we have always used Enterprise WPA over RADIUS against Active Directory/SAMBA to authenticate WiFi access to the office network.
This has now been replaced by, you guessed it, our support tool which creates and stores a unique completely random password for each user in a specific Github Team and offers an API endpoint to be used by the freeRADIUS rlm_rest module to authenticate those users. In order to still have Wifi even when our office internet access is unavailable (though I can’t really see why we’d need that given our reliance on cloud-based services), I added a local proxy in front of such API endpoint that serves a stale response in case of errors (for some hours – long enough for us to be able to fix the internet outage but short enough to not let no-longer-authenticated users access the network).
With this last step, our final dependency on LDAP was finally dropped and all our our identity management is now out-sourced to GitHub, so I could finally issue that one last command
shutdown -h now