There was a discussion on HackerNews about Gmail having lost the email in some accounts. One sentiment in the comments was clear:
It’s totally the users problem if they don’t back up their cloud based email.
Personally, I think I would have to agree:
Google is a provider like every other ISP or basically any other service too. There’s no reason to believe that your data is more save on Google than it is any where else. Now granted, they are not exactly known for losing data, but there’s other things that can happen.
Like your account being closed because whatever automated system believed your usage patterns were consistent with those of a spammer.
So the question is: What would happen if your Google account wasn’t reachable at some point in the future?
For my company (using commercial Google Apps accounts), I would start up that IMAP server which serves all mail ever sent to and from Gmail. People would use the already existing webmail client or their traditional IMAP clients. They would lose some productivity, but no single byte of data.
This was my condition for migrating email over to Google. I needed to have a back up copy of that data. Otherwise, I would not have agreed to switch to a cloud based provider.
The process is completely automated too. There’s not even a backup script running somewhere. Heck, not even the Google Account passwords have to be stored anywhere for this to work.
So. How does it work then?
Before you read on, here are the drawbacks of the solution:
- I’m a die-hard Exim fan (long story. It served me very well once – up to saving-my-ass level of well), so the configuration I’m outlining here is for Exim as the mail relay.
- Also, this only works with paid Google accounts. You can get somewhere using the free ones, but you don’t get the full solution (i.e. having a backup of all sent email)
- This requires you to have full control over the MX machine(s) of your domain.
If you can live with this, here’s how you do it:
First, you set up your Google domain as normal. Add all the users you want and do everything else just as you would do it in a traditional set up.
Next, we’ll have to configure Google Mail for two-legged OAuth access to our accounts. I’ve written about this before. We are doing this so we don’t need to know our users passwords. Also, we need to enable the provisioning API to get access to the list of users and groups.
Next, our mail relay will have to know about what users (and groups) are listed in our Google account. Here’s what I quickly hacked together in Python (my first Python script ever – be polite while flaming) using the GData library:
import gdata.apps.service
consumer_key = 'yourdomain.com'
consumer_secret = '2-legged-consumer-secret' #see above
sig_method = gdata.auth.OAuthSignatureMethod.HMAC_SHA1
service = gdata.apps.service.AppsService(domain=consumer_key)
service.SetOAuthInputParameters(sig_method, consumer_key,
consumer_secret=consumer_secret, two_legged_oauth=True)
res = service.RetrieveAllUsers()
for entry in res.entry:
print entry.login.user_name
import gdata.apps.groups.service
service = gdata.apps.groups.service.GroupsService(domain=consumer_key)
service.SetOAuthInputParameters(sig_method, consumer_key,
consumer_secret=consumer_secret, two_legged_oauth=True)
res = service.RetrieveAllGroups()
for entry in res:
print entry['groupName']Place this script somewhere on your mail relay and run it in a cron job. In my case, I’m having its output redirected to /etc/exim4/gmail_accounts. The script will emit one user (and group) name per line.
Next, we’ll deal with incoming email:
In the Exim configuration of your mail relay, add the following routers:
yourdomain_gmail_users:
driver = accept
domains = yourdomain.com
local_parts = lsearch;/etc/exim4/gmail_accounts
transport_home_directory = /var/mail/yourdomain/${lc:$local_part}
router_home_directory = /var/mail/yourdomain/${lc:$local_part}
transport = gmail_local_delivery
unseen
yourdomain_gmail_remote:
driver = accept
domains = yourdomain.com
local_parts = lsearch;/etc/exim4/gmail_accounts
transport = gmail_tyourdomain_gmail_users is what creates the local copy. It accepts all mail sent to yourdomain.com, if the local part (the stuff in front of the @) is listed in that gmail_accounts file. Then it sets up some paths for the local transport (see below) and marks the mail as unseen so the next router gets a chance too.
Which is yourdomain_gmail_remote. This one is again checking domain and the local part and if they match, it’s just delegating to the gmail_t remote transport (which will then send the email to Google).
The transports look like this:
gmail_t:
driver = smtp
hosts = aspmx.l.google.com:alt1.aspmx.l.google.com:
alt2.aspmx.l.google.com:aspmx5.googlemail.com:
aspmx2.googlemail.com:aspmx3.googlemail.com:
aspmx4.googlemail.com
gethostbyname
gmail_local_delivery:
driver = appendfile
check_string =
delivery_date_add
envelope_to_add
group=mail
maildir_format
directory = MAILDIR/yourdomain/${lc:$local_part}
maildir_tag = ,S=$message_size
message_prefix =
message_suffix =
return_path_add
user = Debian-exim
create_file = anywhere
create_directorythe gmail_t transport is simple. The local one you might have to patch up users and groups plus the location where you what to write the mail to.
Now we are ready to reconfigure Google as this is all that’s needed to get a copy of every inbound mail into a local maildir on the mail relay.
Here’s what you do:
- You change the MX of your domain to point to this relay of yours
The next two steps are the reason you need a paid account: These controls are not available for the free accounts:
- In your Google Administration panel, you visit the Email settings and configure the outbound gateway. Set it to your relay.
- Then you configure your inbound gateway and set it to your relay too (and to your backup MX if you have one).
This screenshot will help you:
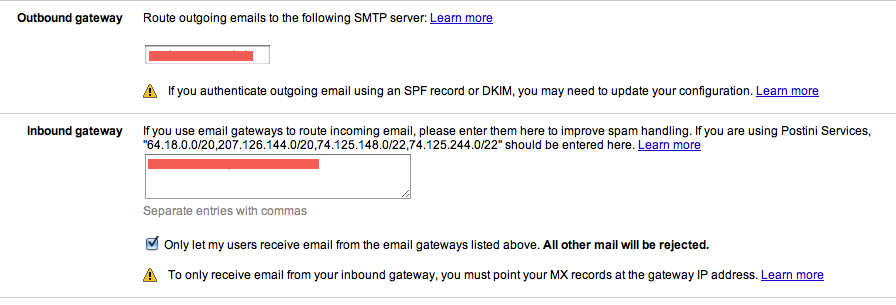
All email sent to your MX (over the gmail_t transport we have configured above) will now be accepted by gmail.
Also, Gmail will now send all outgoing Email to your relay which needs to be configured to accept (and relay) email from Google. This pretty much depends on your otherwise existing Exim configuration, but here’s what I added (which will work with the default ACL):
hostlist google_relays = 216.239.32.0/19:64.233.160.0/19:66.249.80.0/20:
72.14.192.0/18:209.85.128.0/17:66.102.0.0/20:
74.125.0.0/16:64.18.0.0/20:207.126.144.0/20
hostlist relay_from_hosts = 127.0.0.1:+google_relaysAnd lastly, the tricky part: Storing a copy of all mail that is being sent through Gmail (we are already correctly sending the mail. What we want is a copy):
Here is the exim router we need:
gmail_outgoing:
driver = accept
condition = "${if and{
{ eq{$sender_address_domain}{yourdomain.com} }
{=={${lookup{$sender_address_local_part}lsearch{/etc/exim4/gmail_accounts}{1}}}{1}}} {1}{0}}"
transport = store_outgoing_copy
unseen(did I mention that I severely dislike RPN?)
and here’s the transport:
store_outgoing_copy:
driver = appendfile
check_string =
delivery_date_add
envelope_to_add
group=mail
maildir_format
directory = MAILDIR/yourdomain/${lc:$sender_address_local_part}/.Sent/
maildir_tag = ,S=$message_size
message_prefix =
message_suffix =
return_path_add
user = Debian-exim
create_file = anywhere
create_directoryThe maildir I’ve chosen is the correct one if the IMAP-server you want to use is Courier IMAPd. Other servers use different methods.
One little thing: When you CC or BCC other people in your domain, Google will send out multiple copies of the same message. This will yield some message duplication in the sent directory (one per recipient), but as they say: Better backup too much than too little.
Now if something happens to your google account, just start up an IMAP server and have it serve mail from these maildir directories.
And remember to back them up too, but you can just use rsync or rsnapshot or whatever other technology you might have in use. They are just directories containing one file per email.


