When I started running this summer, I also wanted to make use of my Apple watch to keep track of my routes and my speed over time, so I looked into the various apps and services around that.
Generally, there are two parts to tracking a run: One part is the actual data gathering that happens while you’re running and the other part is the analysis and comparison other other runs afterwards.
Unfortunately, of all the applications I looked at, none excelled at both, so in the end what I’ve ended up with is writing custom code to give me the best of both worlds.
Here’s what I’ve looked at.
Apple Workouts.app
The built-in Workout app of the watch, being a watch-native app made by Apple, is more equal than other apps: It’s the only app that allows you to trigger the screen lock while in the app and with WatchOS 4 it’s also the only app that gives you very easy access to the media controls. And finally, it’s the only app that can log its tracked workout and movement Activitiy in the Activitiy app in their actual colors instead of just gray (yes. very important this).
It offers very readable data on-screen while it’s running, it can send timely notifications as you pass another kilometre and it never crashes.
Looking at the Map of the run in the Activity app, it also collects very accurate location data.
As good as it is for collecting data, as bad it is for analysis of the data though: The best you can do is have a look at a single workout. There’s no way to compare two – unless you take screenshots and do that manually.
There is also no way to export the data: In the workout details there is a share button, but that just exports a corny text and a useless picture. No detail is included.

So for any analysis you want to do based on runs recorded with the Workouts app, you have to first manually transfer data from screenshots to some other machine readable form and even then: The screenshots alone don’t provide nearly enough useful data.
Strava
This is the other extreme in the list of apps I looked at: It provides excellent analysis and it has an extremely motivating high-score list for user-provided segments of a run. You don’t have to match routes exactly – the moment you run through an existing previously created segment, you’ll be able to compare your effort to others.
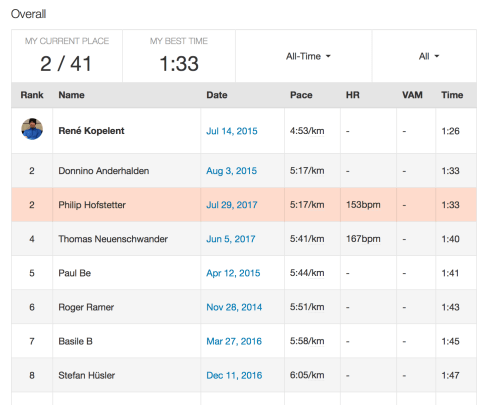
It’s also great at automatically matching previous runs over the same route, so you can compare your runs over time.

The other social features it offers don’t interest me, so I can’t really talk about them.
However: As good as the analysis is, as bad its recording feature is: Of all the apps I looked at it provides the least amount of detail during the run and, what’s worse, its GPS tracking is extremely inaccurate and unreliable.
I’m always running having my phone with me – mainly for easy access to all my media and to Overcast and also because most of my runs I do on my way home from the office where I need the phone anyways. Strava doesn’t make use of this but instead solely relies on the watches GPS which is much less accurate than the phones.
I can understand this: The device is smaller, so it’s harder to put in powerful antennas, it has way less battery and a much weaker CPU than the phone, so it just can’t be as good. It’s totally ok for when you only have the watch with you, but when you have the phone with you, it’s a shame if the app can’t use it.
Runkeeper
Runkeeper uses both the watch and the phone for location tracking and it provides a great UI while the workout is ongoing.
Its analysis features aren’t as good as the ones from Strava though. It doesn’t do the automated segment high-scoring and it’s not as good at comparing runs over the same route with each other.
And finally, the UI of the site doesn’t look as polished as does Strava’s – but that’s just a matter of taste I guess.
… master of none
For all of July and August, my mode of operation was to use Runkeeper to acquire the data during the run and then to export a .gpx file from their site and to import it into Strava.
This gave me the best of both worlds: Very good data gathering and very good data analysis.
However, I wasn’t entirely happy with this either as the process was somewhat cumbersome and, lately, unstable.
Probably caused by iOS 11 Beta, I’ve seen various failure modes related to Runkeeper, all of wich are very annoying:
- The workout might start on the Watch but it will not manage to also start it on the phone. This way, the workout will be tracked, but no route data will be saved.
- Runkeeper on the phone will crash after about 10 minutes. There’s no indication of this happening, but the result will be that a 10 minutes run is logged instead of the real data on the watch. If this happens, there is no way to even just get to the data without the route.
Issue 1) I could work around often by launching Runkeeper manually on the phone, then starting the workout on the watch and then making sure that the workout would also start on the phone.
If that happened, then route data was tracked correctly.
Unfortunately, sometimes, this stopped working all-together and the only way for the watch to talk to the phone again was to completely uninstall and reinstall Runkeeper on both the Phone and the Watch. This is annoying when you want to start running, but you can’t because the Software-gods have put 20 minutes of fiddling with the App Store in front of you (also, Runkeeper is bigger than the App Store’s 3G download limit, so you better have wifi available).
Issue 2) is much worse though: There’s no indication of it happening. You’d think that the blue bar “Runkeeper is actively using your location” on the phone would be a good indicator, but it isn’t: When the crash happens, the bar stays there until you unlock your phone. Then it goes away.
So there’s no way to be sure unless you periodically unlock your phone which is very annoying and distracting during the run – especially as you’re sweaty and TouchID won’t work most of the time (I use a strong 25 character password).
I know – even if it isn’t tracked, a run is a run. But it certainly doesn’t feel that way and how it feels is very important to keep motivated to doing this – especially under bad weather conditions.
let’s just hack it
Now, admittedly, these are very likely beta-woes that will eventually solve themselves. We’re pretty far into the beta cycle though (Beta 9 at the time of this writing), so I’m suspicious that these issues won’t be fixed come release but will have to wait for a future update to either Runkeeper or the OS.
Losing about a third of my runs to software issues felt really unacceptable to me, especially considering that Runkeeper still wasn’t offering some features that the workout app was (like enabling the screen lock – which is important when running in the rain).
However, when I looked again at the WWDC sessions this year, I found out that IOS11 will finally offer an API to read and write route data for workouts. This means that the data you track using Apple’s built-in app will finally be available to other apps to read.
This would give me the best of all worlds: Use the best data-gathering app and export it to the best analysis app; side-stepping the stability issues.
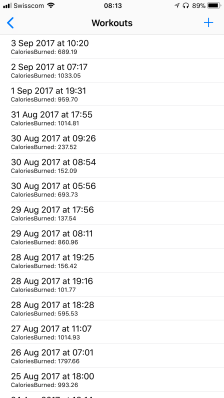
So, this weekend, I hacked together a quick solution (MIT licensed) that does exactly this. It lists you all your workouts and if you tap one, it will eventually show you a share-sheet, allowing you to select a location to store a .gpx file to.
That file contains all the information required for Strava to do its analysis.
In a perfect world, this app would of course upload directly to Strava. And it would not block the UI thread while it’s exporting the gpx file. And it would actually have some UI to speak of.
But this was a quick-hack that solved an issue for me – and who knows – maybe it will fix it for you.
If you need a real solution for this, Twitter user @dwlz is apparently working on a real app that will be usable for normal people and I’ll definitely switch to that when it’s ready. But until then, I can finally track my runs with the peace of mind of having a crash-free solution that still provides the best analysis possible.

 I have slightly altered the logo and the name to make it clear that there’s no affiliation to digitec.
I have slightly altered the logo and the name to make it clear that there’s no affiliation to digitec.


