As explained before, I’ve decided to scratch my own itch and write an independent Apple Watch client for the smide.ch bike sharing service.
The first step to getting from the idea to the final watch app wasn’t actually involving the Watch at all: Before I could get started, I needed to know how the existing smide clients actually work and how to talk to their server.
Then I wanted to have a unit-tested library that I could use from the Watch Frontend.
On top of that library, I wanted to have a command-line client for easier debugging of the library itself.
And only then would I start working on the frontend on the watch.
Preliminaries
So as the Developer Beta 1 for XCode 11, WatchOS 6 and Catalina rolled out, the first few days of development I spent reverse-engineering the official Smide Client.
As always, the easiest solution was to just de-compile their Android Client and lo and behold, they are making use of retrofit to talk to their server which lead to a very nice and readable interface documentation right in my decompiler
Armed with this information, a bit of grepping through the rest of the decompiled code and my trusty curl client, I was able to document the subset of the API that I knew I was going to need for the minimal feature-set I wanted to implement.
In order to have a reference for the future, I have documented the API for myself in the OpenAPI format
This is useful documentation for myself and if I should ever decide to make the source code of this project available, then it’ll be useful for anybody else wanting to write a Smide client.
Moving to XCode: SmideKit
Now that I had the API documentation I needed, the next step was to start getting my SmideKit library going.
Even though there are tools out there that generate REST clients automatically based on an OpenAPI spec, all the tools I looked at produce code that relies on third-party libraries, often Alamofire. As XCode 11 was in a very rough shape already on its own, I wanted to minimize the dependencies on third-party libraries, so in the end, I’ve opted to write my own thin wrapper on top of URLSession
The SmideKit library
SmideKit is a cross-platform (by Apple’s definition) library in that the code itself works across all of Apple’s OSes, but there are individual targets for the individual OSes
But by manually setting the Bundle Name to $(PRODUCT_NAME) in the individual Info.plist files, I can make sure that all projects can just import SmideKit without any suffixes.
As this library is the most crucial part of the overall project, I have written unit testes for all methods to make sure we correctly deal with expiring tokens, unresponsive servers and so on.
The command line client
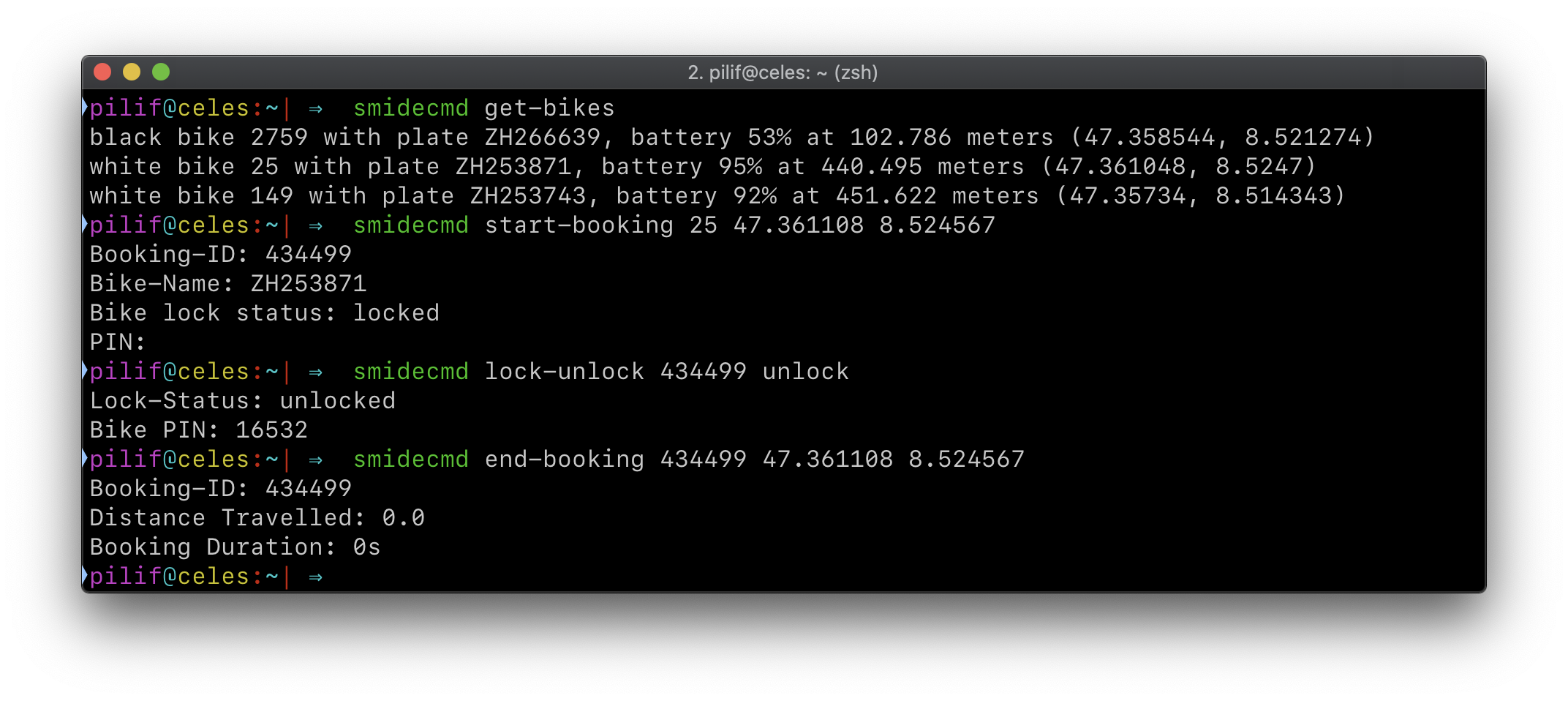
The first user of SmideKit would be a macOs command-line frontend called smidecli. It would offer various subcommands for listing bikes, booking them and ending bookings.
Here’s a screenshot of me booking a bike
Going from nowhere to the working command-line client has taken me the whole period of Beta 1. Two weeks is a long time but between my actual day job and my newly put upon me parenting duties, my time was a bit limited.
Still. It felt good to go from nowhere to writing a library, writing a command-line frontend and then actually using it to book a bike. On the other hand: None of the code written at this point had anything to do with the announcements of WWDC. All work done could just as well have been done on the old SDKs. But still: Having a good foundation to stand on, I was sure was going to pay off.
This year’s WWDC really shook the Apple Ecosystem with probably the most announcements ever happening at a single conference.
Three of the announcements when put together finally pushed me over the line to scratch a personal itch of mine that I was having for a bit more than a year: I’m a very happy customer of the smide.ch bike sharing service here in Zürich, Switzerland: Their electric bikes are well maintained, extremely fun to use and readily available to the point that they have become my main means for transport for my daily commute.
On the other hand, as the Apple Watch has become more and more capable over time between updates to the OS and to the hardware itself to the point where I can now theoretically leave my phone at home and just rely on the watch.
The last remaining hard stopping block was the smide client which so far is only available on the phone, but not on the watch.
So there you see my itch that needed scratching.
In this context, this year’s WWDC was the perfect storm for me: independent Watch apps, SwiftUI and especially SwiftUI on the watch as a real native UI framework unshackled from the constraints of the purely Storyboard based hacks in WatchKit.
The moment I dug through the announcements, I knew: I need to make myself a Smide client and after 3 Beta releases from Apple, that’s what I have done:
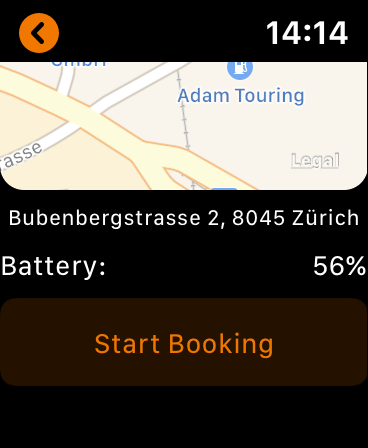
After launching the App and assuming you’re logged in, it lists the bikes around you, sorted by distance to your current location (they have both black (smaller) and white (bigger) bikes – hence the coloring):
Tap any bike and you get a detail view including a map
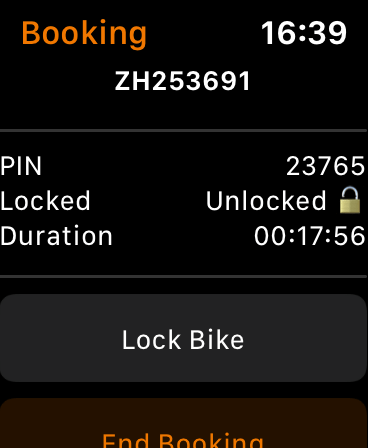
Start the booking and you get some booking information
This feature-set is very limited compared to the official client:
Logging in only works for accounts that were created with an email address and a password. There is no way for my third-party client to possibly work with any oAuth provider
There is no way to report an issue with a bike
The client doesn’t currently take into account the free 10 minute reservation
The official client does some additional user interface activity reporting which my rogue client doesn’t do.
There is zero payment related functionality: As I personally have a 3 year subscription, I don’t need it and besides, this is a rogue client and I can’t and don’t want to deal with their payment system.
Still. This was a fun experience to develop and to keep up-to-date between the various Beta releases, all of which deprecated some essential functionality that was also shown off during conference sessions.
Over the next few days I’m going to write down a development diary like I have done for tempalias back in the days.
To put a bit of a damper on your expectations: As this work is not sanctioned by Smide themselves and as it’s based on reverse-engineering their existing client and because this year’s API for SwiftUI and Combine is still very much in flux, I’m reluctant to release the source code of this.
As I’ve stated previously, I’m subscribed to what is probably the coolest ISP on earth. Between the full symmetric Gbit/s, their stance on network neutrality, their IPv6 support and their awesome support even for advanced things like setting up an IPv6 reverse DNS delegation(!), there’s nothing you could ever wish for from an ISP.
For some time now, they have also provided an IPTV solution as an additional subscription called tv7.
As somebody who last watched live tv around 20 years ago, I wasn’t really interested to subscribe to that. However, contrary to many other IPTV solutions what’s special about the Fiber7 solution is that they are using IP multicast to deliver the unaltered DVB frames to their users.
For people interested in TV, this is great because it’s, for all intents and purposes, lag free as the data is broadcast directly through their network where interested clients can just pick it up (of course there will be some <1ms lag for the data to move through their network plus some additional <1ms lag as your router forwards the packets to your internal network).
As I never dealt with IP multicast, this was an interesting experiment for me, and when they released their initial offering, they provided a test-stream to see whether your infrastructure was multicast ready or not.
Back then, I never got it to work behind my PFSense setup but as I wasn’t interested in TV, I never bothered spending time on this, though it did hurt my pride.
Fast forward to about three weeks ago where I made a comment on twitter about that pride being hurt to the CEO of fiber7. He informed me that the test stream was down, but then he also sent me a DM to ask me whether I was interested in trying out their tv7 offering, including the beta version of their app for the AppleTV.
That was one evil way to nerd-snipe me, so naturally, I told him that, yes, I would be interested, but that I wasn’t really ever going to use it aside of just getting it to work, because live TV just doesn’t interest me.
Despite the fact that it was past 10pm, he sent me another DM, telling me that he has enabled tv7 for my account.
The rest of the night I spent experimenting with IGMP Proxy and the PFSense firewall to some varying success, but on the next day I was finally successful
nachdem mich @kuenzler sowas von nerd-sniped hat gestern Abend, kann ich nun doch den gewünschten Erfolg vermelden.
Ich muss da aber noch ein paar dinge aufräumen bevor ich das als “es funktioniert” bezeichnen könnte. pic.twitter.com/HLfLLijseh
You might notice that this is a screenshot of VLC. That’s no coincidence: While Fiber7 officially only supports the AppleTV app, they also offer links on a support page of theirs to m3u and xspf playlists that can be used by advanced users (which is another case of Fiber7 being awesome), so while debugging to make this work, I definitely preferred to using VLC which had a proper debug log.
After I got it to work, I also found a bug in the Beta version of the Fiber7 app where it would never unsubscribe from a multicast group, causing the traffic to my LAN to increase whenever I would switch channels in the app. The traffic wouldn’t decrease even if the AppleTV went to sleep – only a reboot would help.
I’ve reported this to Fiber7 and within a day or two, a new release was pushed to TestFlight in order to fix the issue.
Since this little adventure happened, Fiber7 has changed their offering: Now every Fiber7 account gets free access to tv7 which will probably broaden the possible audience quite a bit.
Which brings me to the second point of this post: To show you the configuration needed if you’re using a PFSense based gateway and you want to make use of tv7.
First, you have to enable the IGMP proxy:
For the LAN interface, please type in the network address and netmask of your internal IPv4 LAN.
What IGMP Proxy does is to listen to clients in your LAN joining to a multicast group and then joining on their behalf on the upstream interface. It will then forward all traffic received on the upstream aimed at the group to the group on the downstream interface. This is where the additional small bit of lag is added, but this is the only way to have multicast cross routing barriers.
This is also mostly done on your routers CPU, but at the 20MBit/s a stream consumes, this shouldn’t be a problem on more or less current hardware.
Anyways – if you want to actually watch TV, you’re not done yet because even though this service is now running, the built-in firewall will drop any packets related to multicast joining and all actual multicast packets containing the video frames.
So the next step is to update the firewall:
Create the following rules for your WAN interface:
You will notice that little gear icon next to the rule. What that means is that additional options are enabled. The extra option you need to enable is this one here:
I don’t really like the second of the two rules. In principle, you only need to allow a single IP: The one of your upstream gateway. But that might change whenever your IPv4 address changes and I don’t think you will want to manually update your firewall rule every time.
Instead, I’m allowing all IGMP traffic from the WAN net, trusting Fiber7 to not leak other subscriber’s IGMP traffic to my network.
Unfortunately, you’re still not quite done.
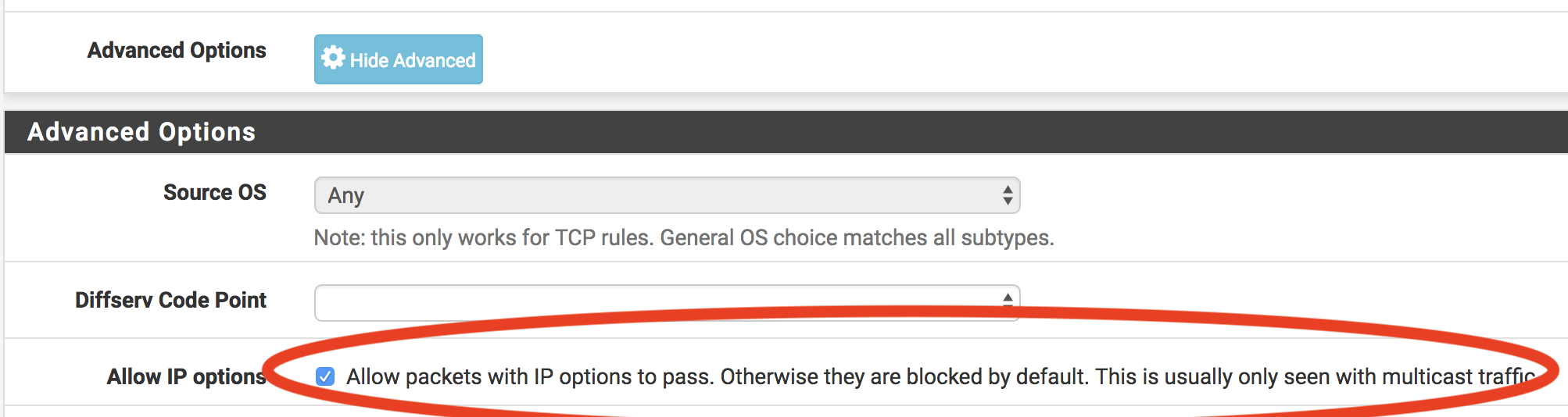
While this configures the rules for the WAN interface, the default “pass all” rule on the LAN interface will still drop all video packets because the above “Allow IP options” checkbox is off by default for the default pass all rule.
You have to update that too on the “LAN” interface:
And that’s all.
The network I’m listing there, 77.109.128.0/19 is not documented officially. Fiber7 might change that at any time at which point your nice setup will stop working and you’ll have to update the IGMP Proxy and Firewall configuration.
In my case, I’ve determined the network address by running
and checking out the error message where igmpproxy was not allowing traffic to an unknown network. I’ve then looked up the network of the address using whois and updated my config accordingly.
Json Web Tokens are all the rage lately. They are lauded as being a stateless alternative to server-side cookies and as the perfect way to use authentication in your single-page app and some people also sell them as a work around for the EU cookie policy because, you know, they work without cookies too.
If you ask me though, I would always recommend against the use of JWT to solve your problem.
Let me give you a few arguments to debunk, from worse to better:
Debunking arguments
It requires no cookies
General “best” practice stores JWT in the browsers local storage and then sends that off to the server in all authenticated API calls.
This is no different from a traditional cookie with the exception that transmission to the server isn’t done automatically by the browsers (which a cookie would be) and that it is significantly less secure than a cookie: As there is no way to set a value in local storage outside of JavaScript, there consequently is no feature equivalent to cookies’ httponly. This means that XSS vulnerabilities in your frontend now give an attacker access to the JWT token.
Worse, as people often use JWT for both a short-lived and a refresh token, this means that any XSS vulnerability now gives the attacker to a valid refresh token that can be used to create new session tokens at-will, even when your session has expired, in the process completely invalidating all the benefits of having separate refresh and access tokens.
“But at least I don’t need to display one of those EU cookie warnings” I hear you say. But did you know that the warning is only required for tracking cookies? Cookies that are required for the operation of your site (so a traditional session cookie) don’t require you to put up that warning in the first place.
It’s stateless
This is another often used argument in favour of JWT: Because the server can put all the required state into them, there’s no need to store any thing on the server end, so you can load-balance incoming requests to whatever app server you want and you don’t need any central store for session state.
In general, that’s true, but it becomes an issue once you need to revoke or refresh tokens.
JWT is often used in conjunction with OAuth where the server issues a relatively short-lived access token and a longer-lived refresh token.
If a client wants to refresh its access token, it’s using its refresh token to do so. The server will validate that and then hand out a new access token.
But for security reasons, you don’t want that refresh token to be re-used (otherwise, a leaked refresh token could be used to gain access to the site for its whole validity period) and you probably also want to invalidate the previously used access token otherwise, if that has leaked, it could be used until its expiration date even though the legitimate client has already refreshed it.
So you need a means to black-list tokens.
Which means you’re back at keeping track of state because that’s the only way to do this. Either you black-list the whole binary representation of the token, or you put some unique ID in the token and then blacklist that (and compare after decoding the token), but what ever you do, you still need to keep track of that shared state.
And once you’re doing that, you lose all the perceived advantages of statelessness.
Worse: Because the server has to invalidate and blacklist both access and refresh token when a refresh happens, a connection failure during a refresh can leave a client without a valid token, forcing users to log in again.
In todays world of mostly mobile clients using the mobile phone network, this happens more often than you’d think. Especially as your access tokens should be relatively short-lived.
It’s better than rolling your own crypto
In general, yes, I agree with that argument. Anything is better than rolling your own crypto. But are you sure your library of choice has implemented the signature check and decryption correctly? Are you keeping up to date with security flaws in your library of choice (or its dependencies).
You know what is still better than using existing crypto? Using no crypto what so ever. If all you hand out to the client to keep is a completely random token and all you do is look up the data assigned to that token, then there’s no crypto anybody could get wrong.
A solution in search of a problem
So once all good arguments in favour of JWT have dissolved, you’re left with all their disadvantages:
By default, the JWT spec allows for insecure algorithms and key sizes. It’s up to you to chose safe parameters for your application
Doing JWT means you’re doing crypto and you’re decrypting potentially hostile data. Are you up to this additional complexity compared to a single primary key lookup?
JWTs contain quite a bit of metadata and other bookkeeping information. Transmitting this for every request is more expensive than just transmitting a single ID.
It’s brittle: Your application has to make sure to never make a request to the server without the token present. Every AJAX request your frontend makes needs to manually append the token and as the server has to blacklist both access and refresh tokens whenever they are used, you might accidentally end up without a valid token when the connection fails during refresh.
So are they really useless?
Even despite all these negative arguments, I think that JWT are great for one specific purpose and that’s authentication between different services in the backend if the various services can’t trust each other.
In such a case, you can use very short-lived tokens (with a lifetime measured in seconds at most) and you never have them leave your internal network. All the clients ever see is a traditional session-cookie (in case of a browser-based frontend) or a traditional OAuth access token.
This session cookie or access token is checked by frontend servers (which, yes, have to have access to some shared state, but this isn’t an unsolvable issue) which then issue the required short-lived JW tokens to talk to the various backend services.
Or you use them when you have two loosely coupled backend services who trust each other and need to talk to each other. There too, you can issue short-lived tokens (given you are aware of above described security issues).
In the case of short-lived tokens that never go to the user, you circumvent most of the issues outlined above: They can be truly stateless because thank to their short lifetime, you don’t ever need to blacklist them and they can be stored in a location that’s not exposed to possible XSS attacks against your frontend.
This just leaves the issue of the difficult-to-get-right crypto, but as you never accept tokens from untrusted sources, a whole class of possible attacks becomes impossible, so you might even get away with not updating on an too-regular basis.
So, please, when you are writing your next web API that uses any kind of authentication and you ask yourself “should I use JWT for this”, resist the temptation. Using plain opaque tokens is always better when you talk to an untrusted frontend.
Only when you are working on scaling our your application and splitting it out into multiple disconnected microservices and you need a way to pass credentials between them, then by all means go ahead and investigate JWT – it’ll surely be better than cobbling something up for yourself.
Sensational AG is the company I founded together with a collegue back in 2000. Ever since then, we had a very nice combination of fun, interesting work and a very successful business.
We’re a very small team – just six programmers, one business guy and a product designer. Me personally, I would love to keep the team as small and tightly-knit as possible as that brings huge advantages: No politics, a lot of freedoms for everybody and mind-blowing productivity.
I’m still amazed to see what we manage to do with our small team time and time again and yet still manage to keep the job fun. It’s not just the stuff we do outside of immediate work, like UT2004 matches, Cola Double Blind Tests, Drone Flights directly from the roof of our office, sometimes hosting JSZurich and meetups for the Zurich Clojure User group and much more – it’s also the work itself that we try to make as fun as possible for everybody.
Sure – sometimes, work just has to be done, but we try as much as possible to distribute the fun parts of the work between everybody. Nobody has to be a pure code monkey; nobody constanly pulls the “change this logo there for the customer” card (though, that card certainly exists to be pulled – we just try to distribute it).
Most of the work we do flows into our big eCommerce project: Whenever you order food in a restaurant here in Switzerland, if the restaurant is big enough for them to get the food delivered to them, the stuff you eat will have been ordered using the product of ours.
Whenever you visit a dentist, the things they put in your mouth likely have been ordered using the product of ours.
The work we do helps countless people daily to get their job done more quickly allowing them to go home earlier. The work we do is essential for the operations of many, many companies here in Switzerland, in Germany and in Austria.
From a technical perspective, the work we do is very interesting too: While the main part of the application is a web application, there are many components around it: Barcode Scanners, native Smartphone applications and our very own highly available cluster (real, physical hardware) that hosts the application for the majority of our customers.
As even our end users slowly start to use their mobile phones more and more, so do our native mobile applications gain in importance to the point where we really have to focus a lot more resources on them.
This is where you come in: In order to provide the best possible user experience, we have decided to develop our offlline-first, native mobile applications separately for both iOS and Android and while we have Android pretty much covered, iOS is lagging behind a bit
If you’re interested to help us out with iOS, here’s what you will be working with.
The application is written in Swift, so you’ll likely use a lot of Swift during your day, however, we don’t mind if you decide you prefer to use something else.
The native application talks to a web service API of our main web application. But as the API is mostly private, you have the ability to directly influence the application in many cases.
As some parts of the process are very customizable, we’re looking into embedding react native views into the existing application.
As we maintain our applications for a long time, code-archeology is an important part of our work. And archeology is much more easily done with useful self-contained commits, so you’ll likely have a bit of a culture-shock when you see us use every nook and cranny of git’s feature-set. But don’t worry: We’ll help you get up to speed quickly.
We have bi-weekly meetings focussed on development practices and challenges we’ve overcome. You will have the direct ability to influence how we work together.
The platform we use to develop on is everybodys own choice. Everybody here uses Macs, but whatever you are most productive with is what you use, though as we’re talking mostly iOS development here, you’re probably going to use a Mac. Be it an iMac or a MacBook Pro – you tell us what you need and we’ll make it possible.
All of the code that we work with daily is home-grown (minus some libraries, of course). We control all of it and we get to play with all the components of the big thing. No component can’t be changed, though we certainly prefer changing some over the others :-)
Between the Cola tests and the technical versatility and challenges described above: If I can interest you, dear reader, to join our crazy productive team in order to improve one hell of a suite of applications, then now is your chance to join up: We need more people
to join our team of developers.
Also, if your particular problem is better solved in $LANGUAGE of your choice, feel free to just do it. Part of the secret behind our productivity is that we know our tools and know when to use them. Good code is readable in any language (though I’d hve to brush up my lisp if you chose to go that route).
When I started running this summer, I also wanted to make use of my Apple watch to keep track of my routes and my speed over time, so I looked into the various apps and services around that.
Generally, there are two parts to tracking a run: One part is the actual data gathering that happens while you’re running and the other part is the analysis and comparison other other runs afterwards.
Unfortunately, of all the applications I looked at, none excelled at both, so in the end what I’ve ended up with is writing custom code to give me the best of both worlds.
Here’s what I’ve looked at.
Apple Workouts.app
The built-in Workout app of the watch, being a watch-native app made by Apple, is more equal than other apps: It’s the only app that allows you to trigger the screen lock while in the app and with WatchOS 4 it’s also the only app that gives you very easy access to the media controls. And finally, it’s the only app that can log its tracked workout and movement Activitiy in the Activitiy app in their actual colors instead of just gray (yes. very important this).
It offers very readable data on-screen while it’s running, it can send timely notifications as you pass another kilometre and it never crashes.
Looking at the Map of the run in the Activity app, it also collects very accurate location data.
As good as it is for collecting data, as bad it is for analysis of the data though: The best you can do is have a look at a single workout. There’s no way to compare two – unless you take screenshots and do that manually.
There is also no way to export the data: In the workout details there is a share button, but that just exports a corny text and a useless picture. No detail is included.
Yes. This is all you get from exporting a run. I love the picture. So useful.
So for any analysis you want to do based on runs recorded with the Workouts app, you have to first manually transfer data from screenshots to some other machine readable form and even then: The screenshots alone don’t provide nearly enough useful data.
Strava
This is the other extreme in the list of apps I looked at: It provides excellent analysis and it has an extremely motivating high-score list for user-provided segments of a run. You don’t have to match routes exactly – the moment you run through an existing previously created segment, you’ll be able to compare your effort to others.
Segment rankings (this segment is uphill)
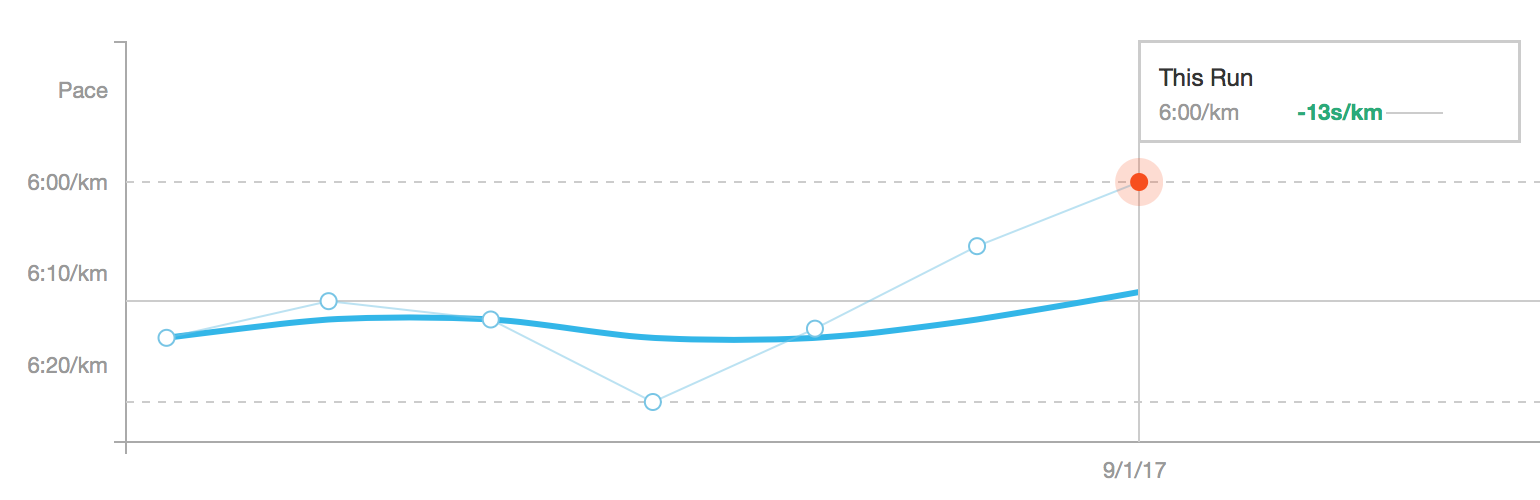
It’s also great at automatically matching previous runs over the same route, so you can compare your runs over time.
Getting faster over time (this mostly uphill too)
The other social features it offers don’t interest me, so I can’t really talk about them.
However: As good as the analysis is, as bad its recording feature is: Of all the apps I looked at it provides the least amount of detail during the run and, what’s worse, its GPS tracking is extremely inaccurate and unreliable.
I’m always running having my phone with me – mainly for easy access to all my media and to Overcast and also because most of my runs I do on my way home from the office where I need the phone anyways. Strava doesn’t make use of this but instead solely relies on the watches GPS which is much less accurate than the phones.
I can understand this: The device is smaller, so it’s harder to put in powerful antennas, it has way less battery and a much weaker CPU than the phone, so it just can’t be as good. It’s totally ok for when you only have the watch with you, but when you have the phone with you, it’s a shame if the app can’t use it.
Runkeeper
Runkeeper uses both the watch and the phone for location tracking and it provides a great UI while the workout is ongoing.
Its analysis features aren’t as good as the ones from Strava though. It doesn’t do the automated segment high-scoring and it’s not as good at comparing runs over the same route with each other.
And finally, the UI of the site doesn’t look as polished as does Strava’s – but that’s just a matter of taste I guess.
… master of none
For all of July and August, my mode of operation was to use Runkeeper to acquire the data during the run and then to export a .gpx file from their site and to import it into Strava.
This gave me the best of both worlds: Very good data gathering and very good data analysis.
However, I wasn’t entirely happy with this either as the process was somewhat cumbersome and, lately, unstable.
Probably caused by iOS 11 Beta, I’ve seen various failure modes related to Runkeeper, all of wich are very annoying:
The workout might start on the Watch but it will not manage to also start it on the phone. This way, the workout will be tracked, but no route data will be saved.
Runkeeper on the phone will crash after about 10 minutes. There’s no indication of this happening, but the result will be that a 10 minutes run is logged instead of the real data on the watch. If this happens, there is no way to even just get to the data without the route.
Issue 1) I could work around often by launching Runkeeper manually on the phone, then starting the workout on the watch and then making sure that the workout would also start on the phone.
If that happened, then route data was tracked correctly.
Unfortunately, sometimes, this stopped working all-together and the only way for the watch to talk to the phone again was to completely uninstall and reinstall Runkeeper on both the Phone and the Watch. This is annoying when you want to start running, but you can’t because the Software-gods have put 20 minutes of fiddling with the App Store in front of you (also, Runkeeper is bigger than the App Store’s 3G download limit, so you better have wifi available).
Issue 2) is much worse though: There’s no indication of it happening. You’d think that the blue bar “Runkeeper is actively using your location” on the phone would be a good indicator, but it isn’t: When the crash happens, the bar stays there until you unlock your phone. Then it goes away.
So there’s no way to be sure unless you periodically unlock your phone which is very annoying and distracting during the run – especially as you’re sweaty and TouchID won’t work most of the time (I use a strong 25 character password).
I know – even if it isn’t tracked, a run is a run. But it certainly doesn’t feel that way and how it feels is very important to keep motivated to doing this – especially under bad weather conditions.
let’s just hack it
Now, admittedly, these are very likely beta-woes that will eventually solve themselves. We’re pretty far into the beta cycle though (Beta 9 at the time of this writing), so I’m suspicious that these issues won’t be fixed come release but will have to wait for a future update to either Runkeeper or the OS.
Losing about a third of my runs to software issues felt really unacceptable to me, especially considering that Runkeeper still wasn’t offering some features that the workout app was (like enabling the screen lock – which is important when running in the rain).
However, when I looked again at the WWDC sessions this year, I found out that IOS11 will finally offer an API to read and write route data for workouts. This means that the data you track using Apple’s built-in app will finally be available to other apps to read.
This would give me the best of all worlds: Use the best data-gathering app and export it to the best analysis app; side-stepping the stability issues.
Such Wow. Much UI.
So, this weekend, I hacked together a quick solution (MIT licensed) that does exactly this. It lists you all your workouts and if you tap one, it will eventually show you a share-sheet, allowing you to select a location to store a .gpx file to.
That file contains all the information required for Strava to do its analysis.
In a perfect world, this app would of course upload directly to Strava. And it would not block the UI thread while it’s exporting the gpx file. And it would actually have some UI to speak of.
But this was a quick-hack that solved an issue for me – and who knows – maybe it will fix it for you.
If you need a real solution for this, Twitter user @dwlz is apparently working on a real app that will be usable for normal people and I’ll definitely switch to that when it’s ready. But until then, I can finally track my runs with the peace of mind of having a crash-free solution that still provides the best analysis possible.
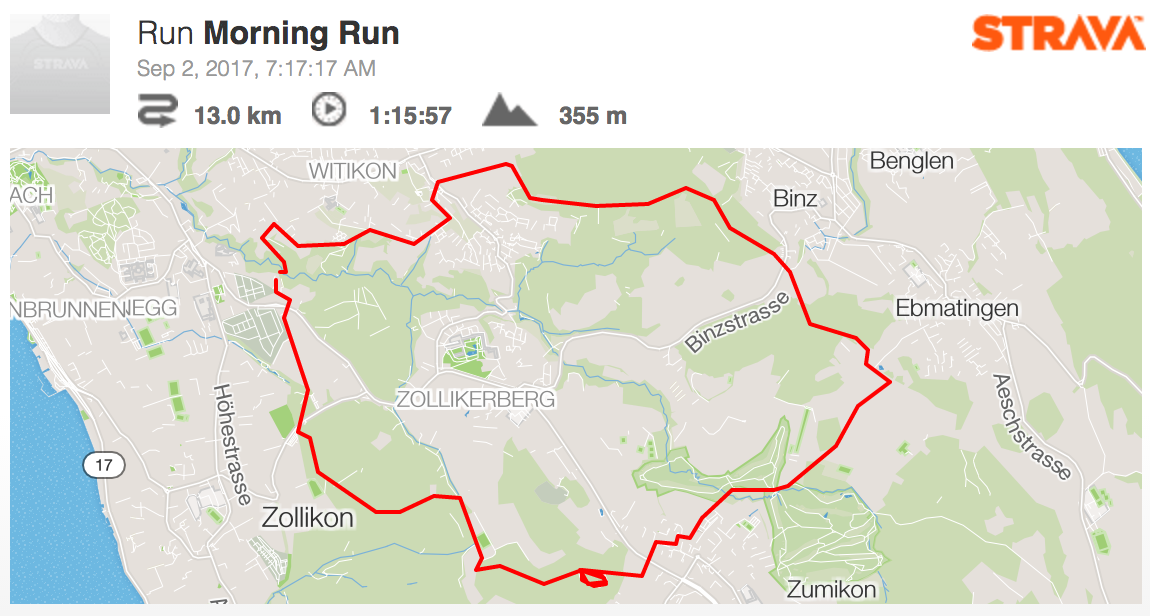
A run tracked with the Workout app and uploaded to Strava using my hack
Last year, when I talked about finally seeing the Apple Watch becoming mildly useful, I had no idea what kind of a ride I was going to be on.
Generally, I’m not really concerned about my health nor fitness, but last September, when my wonderful girlfriend left for a year of study in England, I decided that I finally had enough and I wanted to lose weight.
Having a year of near-zero social obligations would totally allow me to adjust my life-style in a way that’s conducive to weight loss, so here’s what I started doing:
During weekdays, I greatly reduced my calorie intake to basically just a salad and a piece of bread every day (you can pry my bread from my cold dead hands – it’s the one food I think I like the most).
Every day, no matter the weather, no matter the workload, no matter what, I was going to walk home after my work-day in the office, or on weekends, I would just take an equivalent walk.
Every day, I wanted to fill the “Activity” and the “Exercise” rings on my apple watch.
Now walking home sounds like nothing special, but I’m privileged to live in Zürich Switzerland, which means that I have very easy access to forests to walk in.
So commuting home by foot meant that I could walk at least 8 kilometres (4.9 miles), climbing 330m (1082 feet), most of it through the forest.
Every day, no matter whether it was way too hot, way too cold, whether it was raining, hailing or snowing, I would walk home. And every day I would be using my Apple Watch to track what I would generously call a “Workout” (even though it was just walking – but if you go from zero sports to that, I guess it’s ok to call it that).
From September to December I started gradually increasing the distance I walk.
This is the other great thing about Zürich: Once you reach the forest (which you do by walking 20 minutes in practically any direction), you can stay in the forest for hours and hours.
First I extended the 8km walk to 10km, then 12, then 14 and finally 19 (11 miles).
During that time, I kept tracking all the vital signs I could track between the Apple Watch and a Withings scale I bought 1-2 months into this.
My walks got faster and my heart rate at rest got lower and lower, from 80 to now 60.
Every evening after the walk, I would look at the achievements handed out by my Watch which is also why I’ve never updated my movement goals in the Activity app because getting all these badges, honestly, was a lot of fun and very motivational. Every evening I would get notified of increasing my movement streak, of doubling or even tripling my movement goal and of tripling or quadrupling my exercise goal.
Every morning I would weigh myself and bask in the glory of the ever falling graph painted by the (back then very good) iOS app that came with the scale. I would manage to lose a very consistent 2kg (4.4lbs) per week.
Every walk I would have the chance to experience some of natures beauty.
When I got home after up to three hours of walk, I was dead tired at around 10pm, meaning that for the first time in ages I would get more than enough sleep and I would still be able to get up between 6 and 7.
By mid of March, after 6 months of a very strict diet and walking home every day, I was done. I had lost 40kg (88.1 lbs).
Now the challenge shifted from losing weight to not gaining weight. I decided to make the diet less strict but also continue with my walks, though I would not do the regular 19km ones any more as they would just take too long (3 hours).
But by June, I really started to notice a change: I wouldn’t feel these walks at all any more. No sweat, no reasonable change in heart rate while on them, no tiredness. The walks really felt like a waste of time.
So I started running.
I never liked running. I was always bad at it. All the way through school where I was the slowest and always felt really bad afterward, through my life until now where I just never did it. Running felt bad and I hated it.
But now things were different.
The first time I changed from walking to running, I did so after reaching the peak altitude, so it was mostly straight and a little bit downhill. But still: I ran 4km (2.48 miles) and when I got home I didn’t feel much more tired.
I was very surprised because running 4km through all of my life would have been completely unthinkable to me, but there I was. I just did.
So next day, I decided to run most of the way, just skipping the steepest parts. Suddenly, there I was, running 8km (4.9 miles), still not feeling particularly tired afterwards.
So I started tracking these runs (using both Runkeeper and Strava for technical reasons – but that’s another post), seeing improvement in my time all the way through July.
And then, on August 1st, I ran half a Marathon climbing 612m (2007 feet)
Considering that this was my first, it’s not even in too bad a time and what’s even more fun to me: I didn’t even feel too tired afterwards and I totally felt like I could run even farther.
So I guess after taking it very slowly and moving from walking a bit to walking more to walking a lot to running a bit to running some more, even I, the most unathletic person possible can push myself into shape.
But what’s the most interesting aspect in all of this is that without technology, the Apple Watch in particular, without the cheesy achievements, none of this would ever have been possible. I hated sports and I’m honestly still not really interested. But the prospect of getting awarded some stupid batches every day is what finally pushed me.
And now, in only a single month, my girlfriend will finally return to Switzerland and I guess she’ll find me in better shape than she’s ever seen me before in our lives. I hope that the prospect of collecting some more batches from my watch will keep me going even when the social pressure might want to tempt me into skipping a workout.
This blog post is a small list of magic incantations and to be issued and animals to be sacrificed in order to join a Unix machine (Debian in this case) to a (samba-powered) ActiveDirectory domain.
All of these things have to be set up correctly or you will suffer eternal damnation in non-related-error-message hell:
Make absolutely sure that DNS works correctly
the new member server’s hostname must be in the DNS domain of the AD Domain
This absolutely includes reverse lookups.
Same goes for the domain controller. Again: Absolutely make sure that you set up a correct PTR record for your domain controller or you will suffer the curse of GSSAPI Error: Unspecified GSS failure. Minor code may provide more information (Server not found in Kerberos database)
Disable IPv6 everywhere. I normally always advocate against disabling IPv6 in order to solve problems and instead just solve the problem, but bugs exist. Failing to disable IPv6 on either the server or the client will also cause you to suffer in Server not found in Kerberos database hell.
If you made previous attempts to join your member server, even when you later left the domain again, there’s probably a lingering host-name added by a previous dns update attempt. If that exists, your member server will be in ERROR_DNS_UPDATE_FAILED hell even if DNS is configured correctly.
In order to check, use samba-tool on the domain controller samba-tool dns query your.dc.ip.address your.domain.name memberservername ALL
If there’s a hostname, get rid of it using samba-tool dns delete your.dc.ip.address your.domain.name memberservername A ip.returned.above
make sure that the TLS certificate served by your AD server is trusted, either directly or chained to a trusted root. If you’re using a self-signed root (you’re probably doing that), add the root as a PEM-File (but with .crt extension!) to /usr/local/share/ca-certificates/ ad run /usr/sbin/update-ca-certificates. If you fail to do this correctly, you will suffer in ldap_sasl_interactive_bind_s: Can't contact LDAP server (-1) hell (no. Nothing will inform you of a certificate error – all you get is can't connect)
In order to check that everything is set up correctly, before even trying realmd or sssd, use ldapsearch: ldapsearch -H ldap://your.dc.host/ -Y GSSAPI -N -b "dc=your,dc=base,dc=dn" "(objectClass=user)"
Aside of all that, you can follow this guide, but also make sure that you manually install the krb5-user package. The debian package database has a missing dependency, so the package doesn’t get pulled in even though it is required.
All in all, this was a really bad case of XKCD 979 and in case you ask yourself whether I’m bitter, then let me tell you, that yes. I am bitter.
I can totally see that there are a ton of moving parts involved in this and I’m willing to nudge some of these parts in order to get the engine up and running. But it would definitely help if the various tools involved would give me meaningful log output. samba on the domain controller doesn’t log, tcpdump is pointless thanks to SSL everywhere, realmd fails silently while still saying that everything is ok (also, it’s unconditionally removing the config files it feeds into the various moving parts involved, so good luck trying to debug this), sssd emits cryptic error messages (see above) and so on.
Anyways. I’m just happy I go this working and now for reproducing it one more time, but this time recording everything in Ansible.
Even after the Time for Coffee app has been updated for WatchOS 2.0 support last year and my Apple Watch has become significantly more useful, the fact that the complication didn’t get a chance to update very often and the fact that launching the app took an eternity kind of detracted from the experience.
Which lead to me not really using the watch most of the time. I’m not a watch person. Never was. And while the temptation of playing with a new gadget lead to me wearing it on and off, I was still waiting for the killer feature to come around.
This summer, this has changed a lot.
I’m in the developer program, so I’m running this summer’s beta versions and Apple has also launched Apple Pay here in Switzerland.
So suddenly, by wearing the watch, I get access to a lot of very nice features that present themselves as huge user experience improvements:
While «Time for Coffee»’s complication currently is flaky at best, I can easily attribute this to WatchOSes current Beta state. But that doesn’t matter anyways, because the Watch now keeps apps running, so whenever I need public transport departure information and when the complication is flaky, I can just launch the app which now comes up instantly and loads the information within less than a second.
Speaking of leaving apps running: The watch can now be configured to revert to the clock face only after more than 8 minutes have passed since the last use. This is perfect for the Bring shopping list app which now suddenly is useful. No more taking the phone out while shopping.
Auto-Unlocking the Mac by the presence of an unlocked and worn watch has gone from not working at all, to working rarely, to working most of the time as the beta releases have progressed (and since Beta 4 we also got the explanation that WiFi needs to be enabled on the to-be-unlocked mac, so now it works on all machines). This is very convenient.
While most of the banks here in Switzerland boycott Apple Pay (a topic for another blog entry – both the banks and Apple are in the wrong), I did get a Cornèrcard which does work with Apple Pay. Being able to pay contactless with the watch even for amounts larger than CHF 50 (which is the limit for passive cards) is amazing.
Between all these features, I think there’s finally enough justification for me to actually wear the watch. It still happens that I forget to put it on here and then, but overall, this has totally put new life into this gadget, to the point where I’m inclined to say that it’s a totally new and actually very good experience now.
If you were on the fence before, give it a try come next autumn. It’s really great now.
As a customer of digitec, I often deal with their collection notices which I get via email and which invite me to go to their store and fetch my order (yes. I could have the goods delivered, but I’m impatient and not willing to pay the credit card surcharge).
Ever since Passbook happened on iOS 6, I wished for these collection notices to be iOS Passes as they have a lot of usability benefits:
passes are location aware an pop up automatically when you get close to the location
Wallet automatically turns the screen brightness all the way up
passes could potentially be updated remotely
once added to the Wallet, passes don’t clutter your mailbox and you’ll never lose them in the noise of your inbox.
Next time you get a digitec collection notice, just forward it to
digipass@pilif.me
After a few seconds, you will get the same collection notice again, but with the PDF replaced by an iOS Wallet pass that you can add to your Wallet.
I have slightly altered the logo and the name to make it clear that there’s no affiliation to digitec.
The pass will be geo-coded to the correct store, so it will automatically pop up as you get close to the store.
As I don’t want access to your digitec account and because digitec doesn’t have any kind of API, I unfortunately can’t automatically remove the pass when your fetch your order – that’s something only digitec can do.
The source code for the server is available under the MIT license.
Disclaimer:
I’m not affiliated with digitec aside of being a customer of theirs. If they want me to shut this down, I will.
I am not logging the collection notices you’re forwarding me. If you don’t trust me, you can self-host, or redact the notice to contain nothing but the URLs (I need these in order to build the pass).
This is a fun project. If it’s down, it’s down. If it doesn’t work, submit a pull request. Don’t expect any support
The LMTP daemon powering this is running in my home. I have a very good connection, but I also have not signed an SLA or anything. If it’s down, it’s down (the message will get queued though).
The moment I see this being abused, it will be shut down. Just like my previous email based fun project

















 I have slightly altered the logo and the name to make it clear that there’s no affiliation to digitec.
I have slightly altered the logo and the name to make it clear that there’s no affiliation to digitec.